AWS Community Day는 AWS를 사용하는 개발자 및 고급사용자들이 주축이 되어 AWS 서비스 활용 방법 및 사용 대한 정보를 공유하는 기술 컨퍼런스입니다.
지난 1월 25일, 세종대학교에서 개최된 AWS Community Day - re:Invent특집에서는 지그재그 데이터팀의 성운님이 참석해서 AWS Sagemaker Ground Truth에 대해 소개해주셨습니다.
Ground Truth를 통해 데이터 라벨링 노가다(...)를 어떻게 줄일 수 있었는지, 발표 영상과 그 자세한 내용을 공유드립니다. 영상은 여기서 확인하실 수 있습니다!
안녕하세요. 저는 크로키닷컴의 데이터 과학자 소성운이라고 합니다.
저희 크로키닷컴은 여성 쇼핑몰들을 모아서 쉽고 빠르게 보여주는, 개인화된 쇼핑 환경을 제공하는 '지그재그'를 운영하고 있습니다. 남자분들에게는 생소할 수 있겠지만 여성 쇼핑 분야에서는 좋은 성과를 보이고 있는 서비스입니다. 1500만 다운로드, MAU 230만, 자체 광고 플랫폼 매출 200억 등 많은 사용자들이 사랑하는 앱으로 자리 잡고 있습니다.
아무래도 쇼핑을 다루는 앱 서비스이다 보니 사용자 데이터 분석, 개인화 추천 등의 분야에 관심을 가지고 있습니다. 자연스럽게 빅데이터 분석을 위한 EMR이나 Glue, 머신러닝을 위한 Sagemaker 같은 서비스에 관심이 많았습니다. 관심을 쫓아가다 보니 현재는 AWS 유저 그룹에서 커뮤니티 활동도 열심히 하고 있습니다.

오늘 함께 나눌 주제는 머신러닝입니다. 보통 머신러닝이라고 하면 모델링 기법이나 최적화에 대한 내용이 주를 이루는데, 이번 세션은 모델 학습에 사용되는 데이터에 대해서 이야기해보겠습니다.

먼저 Amazon Sagemaker라는 서비스를 간략히 소개드리려고 합니다. Sagemaker는 머신러닝 프로세스인 학습과 최적화, 그리고 배포 단계를 서비스 내에 프로세스화한 형태입니다. 모델 학습을 위한 각종 환경 구성을 원클릭으로 설정할 수 있고, 이렇게 구성된 환경에서 자신이 직접 만든 모델로 클라우드 환경에서 학습이 가능하며, 또한 Sagemaker에 내장된 머신러닝 모델 또한 사용이 가능합니다.
개발 경험이 없는 데이터 분석가나 과학자분들은 자신이 공들여 만든 모델을 서비스에 반영하는 게 큰 챌린지인데, Sagemaker에서는 모델의 배포와 API 생성까지 손쉽게 끝낼 수 있습니다. 제가 Sagemaker를 좋아하는 이유이기도 합니다. 일련의 절차들을 모두 자동화하고 프로세스화 하여, 우리가 집중해야 할 좋은 모델을 만들고 검증하는데 많은 시간을 할애할 수 있도록 도와줍니다.

오늘 소개해드릴 Amazon Sagemaker Ground Truth도 같은 맥락의 서비스라고 보시면 됩니다. 별도의 독립적인 서비스는 아닙니다. 기존 Sagemaker 상에 추가된 기능으로, 모델링 이전에 갖춰야 할 학습 데이터의 퀄리티를 어떻게 높일 것인가에 대한 고민의 결과가 만들어낸 산물이라고 생각합니다.

라벨링이라는 작업은 모델 학습에 사용되는 데이터에 정답을 달아놓는 과정입니다. 많이 보셨을 개와 고양이를 분류하는 모델에 비유하자면, 개와 고양이 이미지에 각각 개 혹은 고양이라는 정답을 달아 놓는 작업입니다. 라벨링 작업은 굉장히 힘이 듭니다. 왜 힘들까요? 라벨링 작업은 노가다 작업으로 느껴질 때가 많기 때문입니다. 우스갯소리로 인형에 눈 붙이는 작업이라고도 합니다.
라벨링이 어려운 첫 번째 이유 중 하나는 머신러닝을 위해서는 많은 양의 데이터가 필요하다는 것입니다. 이미지를 분류하기 위해서는 최소 수천, 수만 장의 이미지가 필요합니다.
라벨링이 어려운 두 번째 이유는 사람이 직접 라벨링을 해야 하기 때문입니다. 오른쪽 이미지들은 Image Segmentation을 위한 데이터셋 예제입니다. 단순히 개나 고양이를 분류하는 작업이 아니라 해결하고자 하는 문제가 복잡할수록 필요한 데이터셋도 점점 더 복잡해집니다. 세 번째 이유는 시간을 포함한 많은 비용이 든다는 것입니다. 그리고 무엇보다, 라벨링 작업자가 많아질수록 일관되고 정확한 라벨링 작업이 어려워집니다.

조금 더 이해를 돕기 위해 제가 요즘에 회사에서 고민하는 내용을 간단히 공유 드릴 건데요 여러분들도 같이 생각해봐 주시면 재밌을 것 같습니다. 지그재그에서는 여성 쇼핑몰의 상품들을 손쉽게 검색할 수가 있는데요, 보시는 화면은 저희 앱, 그러니까 검색 기능에서 기본적으로 제공되는 필터 기능입니다. 제가 목도리를 검색하고, 그중에서 파란색 목도리만 보고 싶어서 색상으로 필터를 한 결과인데요. 이 기능이 제공이 되기 위해서는 각 상품마다 색상 정보가 존재해야 합니다. 그렇다면 이 색상 정보는 어떻게 기입을 할까요? 상품의 이미지를 보고 색상 카테고리에 맞게 색상 정보를 기입하면 됩니다. 참 쉽죠?

그런데 지그재그에 3700개의 쇼핑몰이 입점해있고, 하루에만 약 1만 개의 신상품이 업데이트된다는 것을 고려하면 이야기가 달라집니다. 사람이 이렇게 많은 양의 이미지에 일일이 색상 정보를 입력하는 것은 어려운 일입니다. 머신러닝이 이 문제를 해결해 줄 수 있을까요?

처음 시작한 아이디어는 다음과 같았습니다. '제품 이미지 상에서 제품의 색상을 RGB로 뽑아내고, 이게 어떤 색상인지 학습시키면 색상을 자동 라벨링 할 수 있는 모델을 만들 수 있지 않을까?'

관련된 내용을 작년 핸즈온 세션에서도 다뤘었는데요. 관심 있으신 분은 아래 링크를 참고해보셔도 좋을 것 같습니다. Https://github.com/yansonz/2018-handson-data-02
이때의 내용을 요약해드리자면, 요즘에는 좋은 Vision API가 워낙 많아서 이미지를 넣으면 위와 같이 대표 색상을 RGB 컬러로 뽑아낼 수가 있다는 겁니다. 그래서 관련된 데이터 셋을 만들어봤습니다. RGB 값과 레이블 필드를 보실 수 있습니다. 그런데 여기서 문제가 있습니다.

RGB 값으로 봤을 때 과연 어디까지를 파란색이라고 볼 수 있을까요?
같은 이미지에 있는 색상이어도 사람마다 기준이 다르기 때문에 어떤 사람은 파란색이라고 하고 어떤 사람은 남색이라고 하겠죠. 라벨링 작업이 일관되게 이루어지기가 굉장히 어려운 상황이 발생합니다. (당시 저희 팀에서 해당 타스크는 저만의 기준을 세워서 혼자 진행했습니다)

이렇게 어렵고, 막막할 수 있는 라벨링 작업이 왜 이렇게 중요한 걸까요?
좋은 머신러닝 모델을 만드는 것은 당연히 좋은 결과를 만들어내는 성공의 열쇠입니다. 그러나 좋은 머신러닝 모델만큼이나 중요한 것은 좋은 학습 데이터 입니다. 좋은 학습 데이터가 좋은 모델을 만드는데 도움이 되기 때문입니다.
장표에 예시로 등장한 데이터셋들은 머신러닝 딥러닝에 관심이 있으신 분이라면 한 번쯤 보았을 것들인데요, 대표적으로 이미지넷 데이터셋을 보았을 때, 총 1400만 개의 이미지를 2만 개가 넘는 카테고리로 라벨링을 해둔 데이터입니다. 다른 것들도 여러 사람이 직접 한 땀 한 땀 라벨링 한, 검증된, 즉 좋은 퀄리티의 데이터셋들입니다. 머신러닝을 공부하실 때는 이런 데이터셋을 바탕으로 만들어진 모델을 리서치하셔서 사용해보거나 그 모델을 바탕으로 자신만의 모델링을 많이 해보시게 됩니다.
그런데 자신만의 비즈니스가 존재할 때는 다양한 문제를 머신러닝으로 실전에서 해결해야 하고, 이 문제들에 맞는 자신만의 데이터셋을 만들어야 할 때가 있습니다. 그때는 지금까지 말했던 많은 문제들에 직면하게 됩니다. 바로 그때 당황하지 마시고 Sagemaker Ground Truth를 써보시면 큰 도움이 됩니다.

왜냐하면 Sagemaker는 이러한 라벨링 작업마저도 머신러닝 프로세스의 일부로 여기고, 이것을 서비스화 시켰기 때문입니다. 또, 아마존이 했기 때문에 기대할 수 있는 것들이 분명 있죠. 완전 관리형, 효율화, 자동화, 확장성 등등 많은 장점들이 있습니다.

Ground Truth에서 제공 가능한 라벨링 작업은 총 5가지입니다. Object Detection에서 사용되는 바운딩 박스 작업, Image Classficiation에 사용되는 형태의 작업, Semantic Segmentation, Text Classifiation 입니다. 여러분들이 람다와 개발코드에 익숙하다면 자신만의 라벨링 작업 환경 또한 직접 구축하실 수 있습니다.

라벨링 작업을 Ground Truth를 통해 하게 되면, 관리 형태의 작업을 할 수 있을 뿐만 아니라 예상치 못한 선물 등의 기능들을 만나보실 수도 있습니다. 예를 들면 액티브 러닝과 오토 라벨링 기능입니다. 우선 간략하게 서비스 데모를 보신 후에 이 기능들에 대해서 이야기해보겠습니다.

작업팀은 라벨링을 다양한 형태로 구성할 수 있는데요. 그 작업팀을 워크포스라 하며, 총 세 가지 형태가 제공됩니다. Public은 간단히 말하면 라벨링 작업을 온라인 프리랜서에게 외주를 주는 것입니다. Private은 데이터의 특수성이나 보안 이슈로 조직 내 팀을 구성하는 형태이고요, Vendor 옵션은 라벨링 전문팀에게 의뢰하는 형태입니다.

데모는 Private 워크포스를 구성하고, 간단한 예제인 개와 고양이의 이미지를 분류하는 모델을 위해 데이터셋을 만든다는 가정에서 진행했습니다. Ground Truth는 아직 서울 리전에 론칭이 되지 않았기 때문에 북미리전으로 진행했습니다.
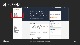
먼저 Sagemaker 콘솔에 가보시면 상단에 Ground Truth 메뉴가 생긴 것을 확인해 볼 수 있습니다. 작업을 만드는 것은 굉장히 쉽습니다. 메뉴에서 라벨링 잡을 하나 만들면 됩니다.
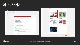
잡을 만드는 과정입니다. 잡의 이름과 내가 작업할 이미지들이 있는 S3 주소를 넣어줍니다. S3에 이미지 넣어두기 때문에 용량 걱정 없이 수십만 장의 이미지를 넣어두셔도 됩니다. 해당 경로에 이미지가 있으면, 라벨링 작업의 메니페스토라는 json으로 입력값 정리가 됩니다. 마찬가지로 작업의 결과는 지정해둔 아웃풋 s3 경로에 json 형태로 저장이 됩니다. 전에 소개드렸던 라벨링 작업의 형태를 정의할 수 있습니다, 이 데모에서는 바운딩 박스 작업을 해보고자 합니다.

저는 외주작업을 의뢰해서 비용이 많이 나가는 것을 피하고 싶었습니다. 때문에 작업자를 Private으로 지정했고, Private 워크포스 내에는 총 세명의 작업자를 지정해두었습니다. 다음으로 가장 중요한 작업자를 위한 작업환경 페이지 구성인데요. 오른쪽을 보시면 해당 이미지에서 바운딩 박스를 그려야 할 레이블을 명시해두었습니다(여기서는 고양이죠) 그리고 바운딩 박스를 어떻게 그려야 한다는 클리어한 작업설명이 있습니다. 작업설명 부분은 이해하기 쉽고 간결해야 합니다. 때문에 좋은 예와 나쁜 예를 이미지로 보여주는 형태가 가장 효과적이라고 느껴졌습니다.
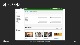
작업 화면 구성까지가 끝나면 모든 작업환경 구성이 완료가 된 것입니다. 완료가 되고 나면 이와 같이 해당 작업의 상태(전체 이미지 중 어디까지 누가 작업을 진행했는지, 해당 작업의 이미지 정보들이 무엇인지를 볼 수 있는 관리 페이지가 생깁니다.
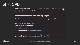
작업환경 구성이 완료되면 수분 이내에 작업자에게 이메일이 발송됩니다. 이메일에는 작업환경으로 접속할 수 있는 접속 주소, 로그인을 위한 아이디, 비번 정보가 있고, 해당 정보들로 로그인을 하게 되면,

화면에서 과 같이 조금 전에 작업을 구성해둔 페이지 그대로 작업자가 만나볼 수 있습니다. 아래에는 바운딩 박스를 그릴 수 있는 툴이 있으며 할당된 개수의 이미지를 모두 끝낼 때까지 연속적으로 작업 진행이 가능합니다.

작업한 내용은 보시는 것처럼 json 형태로 아웃풋 경로로 지정해둔 S3에 적재되는데, 이 정보들은 원본 이미지와 함께 Sagemaker에서 훈련 데이터셋으로 사용이 가능합니다.

보시는 것과 같이 Ground Truth는 대규모의 라벨링 작업을 수십/수백 명의 작업 자이 무리 없이 진행할 수 있도록, 쉽고 편리한 작업 인터페이스가 제공이 되고 있습니다. 세션 초반에 제품 색상 분류 사례를 소개하면서 여러 작업자들 간의 라벨링의 퀄리티를 어떻게 유지할 수 있을까에 대한 문제를 언급했습니다.

가장 간단하게, 쉽게 떠오르는 방법은 다수결 원칙에 따르는 것입니다. 여러 작업자들 간에 각기 다른 라벨링 결과를 통합할 때를 예로 들어보겠습니다. 왼편의 강아지 사진을 보고 네 명의 작업자 중 세명은 불독, 한 명은 샤페이라고 답했습니다. 그러면 다수결의 원칙에 따라 해당 이미지는 불독으로 분류가 될겁니다. 하지만 이게 최선일까요?

확률 모델을 적용하는 방법도 있습니다. 라벨링 작업을 여러 라운드로 진행하면서, 네 명의 작업자 중 빨간색 작업자의 라벨링의 정확도가 다른 작업자에 비해 높다고 가정해 봅시다. 작업자들의 정확도는 각 사람마다 수치화되어있습니다. 이번 경우에도 이전과 같이 불독, 샤페이, 불독, 불독이라고 대답했습니다. 약간 복잡해 보이는 수식이 나왔지만, 간단히 설명드리면 이 라벨링 작업의 결과가 샤페이일 확률은 불독일 확율보다 10배 높습니다. 그 이유는 작업자의 정확도를 고려하기 때문입니다. 또한 이 라벨링 작업의 결과는 단순히 이 이미지는 불독이다! 샤페이다! 가 아니라 0.9의 Confidence로 샤페이, 0.1의 Confidence로 불독일 것이다라고 분류가 됩니다. 일반적인 다수결 원칙보다 조금 더 합리적이고 나이스 한 결과입니다.

다음으로 말씀드리고 싶은 부분은 액티브 러닝과 오토 라벨링에 대한 부분입니다. 데모 과정에서는 해당 기능을 켜 두진 않았는데요, 작업해야 할 이미지 수가 많은 경우에, 특히 수만 장 이상 이미지를 다뤄야 하는 경우에는 적극적으로 활용해볼 만한 기능입니다.

지금까지 봐왔던 내용들은 작업자를 통해서 라벨링 작업이 이뤄지고 그 결과들을 병합하는 Consolidation 작업까지 이루어진 후에 최종 결과가 산출되는 시나리오였습니다. 도식화된 내용을 설명드리면, Ground Truth에서는 뒷단에 딥러닝으로 학습되는 모델이 존재하고 여러분들의 입력 이미지들을 딥러닝 모델이 자동 분류를 하게 됩니다. 이때 분류의 결과가 지정된 스레드 홀드보다 높은 정확도를 가졌다면 자동으로 라벨링이 되고, 그 이하면 즉 정확도가 낮은 분류라면 사람 작업자에게 보내어 분류가 되도록 워크플로우가 짜여 있습니다. 사람이 분류해낸 결과는 다시 딥러닝 모델의 학습 데이터로 사용되어 라벨링 작업이 진행되면 진행될수록 이 모델의 성능 역시 함께 증가하게 됩니다. 이를 액티브 러닝이라고 하고 사람이 아닌 모델을 통해 자동 분류되는 형태의 라벨링을 오토 라벨링이라고 합니다.
여러분들이 Ground Truth를 이용해서 라벨링 작업을 한다면 별다른 노력 없이 작업 생성하실 때 옵션 체크 유무만으로 이런 베네핏을 모두 가져갈 수 있습니다.


전반적인 성능에 관한 지표들입니다. 범례에 주황색 MTruk는 사람 작업자를 의미하고, 초록색 Auto only는 조금 전에 보신 딥러닝 모델을 통한 오토 라벨링 작업, 파란색 Ground Truth는 이 두 가지 작업을 동시에 이용하는 케이스를 말합니다. 첫 번째 그래프를 보시면 x축을 따라 사람이 진행한 라벨링 수가 증가할수록, 주황색인 사람 작업자의 결과는 그에 맞춰서 선형적으로 증가하는 것을 확인할 수 있습니다. 오토 라벨링의 경우는 처음에 처리되는 라벨링 수가 좋지 못하다가 사람의 작업량이 늘어나면서 모델 학습이 이루어지고 정확도도 증가하면서, 처리되는 작업량도 늘어나는 것을 볼 수 있습니다.
따라서 Ground Truth의 결과는 두 가지 작업의 합산입니다. 동일한 작업 양, 시간 동안 높은 퍼포먼스를 가져갈 수 있다는 것을 확인할 수 있습니다. 바로 아래 그래프는 정확도에 관한 지표입니다. x축을 따라 사람이 라벨링 하는 이미지가 증가할수록 모델의 정확도가 목표한 90% 정확도로 수렴하는 것을 보실 수 있습니다. 오른쪽 상단에 세 번째 그래프는 비용에 관련된 지표인데, 이미지 장당 사람에게 의뢰하는 비용은 5센트로 고정입니다, 모델의 정확도가 증가하면서 실패 확률이 낮아지고 장당 처리되는 비용이 현저히 떨어지는 것을 볼 수 있습니다. 그래서 전반적으로 사람으로 운용되는 라벨링 작업보다 Ground Truth에서 사람과 오토라벨링을 함께 운용하는 것이 비용적인 측면에서도 절감 효과가 있습니다.

아마존 Sagemaker와 신규 서비스인 Ground Truth를 써보면서 느낀 점은 머신러닝을 잘 알건 모르건 간에 일단 시작을 할 수 있게 만들어준다는 것입니다.
여러분들이 머신러닝을 통해서 현실의 문제를 해결하고자 할 때 시작하기도 전에 예상치 못하는 다양한 어려움에 직면하게 됩니다. 작업환경 구축하는 건 너무나 고되고, 모델 학습이나 파라미터 튜닝 과정은 너무 많은 시간이 소요돼서 쉽게 지치기 마련입니다. Sagemaker는 이런 과정들을 프로세스화 했고 쉽게 사용 가능한 툴을 제공함으로써, 자칫 부수적인 작업이라고 느낄 수 있는(흔히 말하는 삽질) 해결하였고, 본래 하고자 했던 더 나은 모델, 정확도가 높은 모델을 만드는데 시간과 노력을 쏟게 해 주었습니다.
신규 서비스인 Groud Truth는 마찬가지로 Sagemaker가 구축해놓은 탄탄하고 유연한 머신러닝 환경 속으로 라벨링 작업을 들여왔고, 퀄리티 있는 대용량의 데이터셋을 구축할 수 있게 해 주었습니다. 여러분들이 자신만의 데이터로 머신러닝 프로젝트를 진행해보고 싶다면 꼭 이용해보시길 바랍니다.
감사합니다.
---
지그재그 데이터팀과 개발팀에서는 쇼핑 데이터와 관련된 다양한 프로젝트들을 적극적으로 진행하고 있습니다. 지그재그 팀과 함께, 국내에서 가장 많은 패션 데이터를 다뤄보고 싶으신 분들의 지원을 언제나 기다리고 있습니다.
job@zigzag.kr
https://career.zigzag.kr/recruit
 가입하기
가입하기



