안녕하세요. 왓챠입니다.
왓챠(앱)에서는 하루에 수천 개의 코멘트가 작성됩니다.
수천 개의 코멘트가 작성되는 만큼 다양한 생각들을 남겨주십니다. 그래서 왓챠는 “취향 존중의 원칙”을 전제로 한 상대방 코멘트에 대한 공감 / 질문 / 반론을 권장합니다. 그러나 다음과 같은 상황은 “취향 존중의 원칙”이 지켜지지 않은 것이라고 생각합니다.
기준에 대한 일부 예시 입니다.
글쓴이 취향 자체에 대한 공격
특정 계층, 지역, 종교에 대한 공격
심한 욕설이 포함된 경우
성적 비하 또는 모욕을 한 경우
“취향 존중의 원칙”이 지켜지지 않을 경우 해당 코멘트 및 대댓글은 부적절 처리되고, 나만 볼 수 있도록 변경됩니다. 사람이 하루에 수천 개의 코멘트를 읽어 나가면 부적절한 텍스트를 분류하기에 물리적으로 힘들어, 유저들의 신고에 의존하고 있었습니다.
[예시1]
후회 용서 아 예 인생 좆같은거 당연한건데 + wise up 노래 나올때 ... 실소가
[예시2]
좆같다ㅋㅋ
하루가 다르게 발전하고 있는 머신러닝 자연어처리를 이용하여 부적절한 텍스트를 자동으로 분류 하기위해 프로젝트를 시작했습니다.
많은 공개된 머신러닝 알고리즘이나 케글(kaggle)에 나오는 문제들은 다음과 같은 특징이 있습니다.
참고할만한 자료
데이터셋
모델의 성능을 비교할만한 대상
하지만 참고할 만한 자료가 거의 없는 상황에서 데이터는 최소한 얼마나 필요할지, 모델의 성능은 충분히 좋은지, 더 나은 문제 해결방법은 없는지, 실제 서비스에 도입할 만한 수준인지에 대해 전혀 감을 잡을 수 없었습니다.
그래서 처음부터 시작하는 머신러닝 4가지 단계 : 데이터셋의 구축, 전처리 과정, 모델링, 평가에 대해 공유해 보려고 합니다.
[사전지식]
사전지식은 글을 읽어 가나며 조금더 이해를 돕고자 참고하시면 좋을 내용입니다. 생략하셔도 무방합니다.
Character level CNN for text classification
Character-level Convolutaional Neural Network(이하 charCNN)은 CNN의 메커니즘상 지역정보를 잘 표현하고, 많은 정보에서 특징점만 뽑을 수 있는 특성이 있습니다. 더욱이 word representation이 아닌 가장 최소 단위인 문자를 가지고 CNN을 적용하고, 좋은 성능을 보입니다. 문자열을 기반으로 하여 OOV(out of vocab)에 유연하고, 구어체 및 채팅과 같은 형태의 인간오류를 잘 보정해 줍니다.

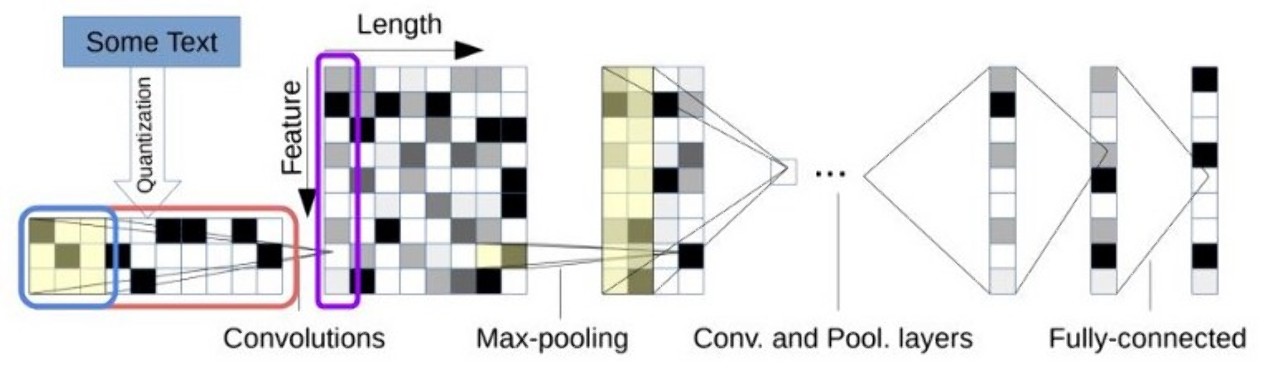
[그림1]charCNN논문에서 사용된 이미지
이 그림은 논문에서 나온 전체적인 charCNN의 메커니즘을 잘 설명해서 가져 왔습니다. charCNN의 메커니즘은 알파벳과 같은 문자를 one-hot encoding 된 문자의 집합에 1014개의 고정된 문자수 만큼 변환해 줍니다.
예를들어 1014개의 고정된 글자수에 [나는 사람이다] 는 [ㄴ,ㅏ,ㄴ,…,…]가 [[0,1,0,…], [0,0,0,…],,,,[…,….,0]] 과 같은 행렬로 표현할수 있습니다. 이를 양자화(quantization) 라고 합니다.
그림에서는 빨간박스가 quantized matrix를 의미합니다. 가로는 문자 수(논문상 70개), 세로는 글자 수(논문상 1014개)를 의미합니다. Quantization 과정중 70개의 문자에 속하지 않거나, 글자 수가 1014개 미만일 경우에는 zero vectors로 대체됩니다. 글자 수의 초과분은 무시합니다.
Quantized matrix를 convolutional computation해주는 과정은 파란 박스와 보라색 박스에서 잘 표현 됩니다. 이미지처리에서 사용되는 convolutional computation와 동일합니다. 차이점은 이미지에서는 2D convolutional layer가 사용되었다면, 여기선 1D convolutional layer가 사용되었습니다.
파란 박스는 커널(kernel)를 의미합니다. 보라색 박스는 feature map을 의미합니다. 보라색 박스가 한 줄인 이유는 1D convolutional layer를 통해 연산되었기 때문입니다. 이미지에서와 마찬가지로 그림에서 length로 표현되는 게 feature map의 개수를 가르킵니다.
그 이후의 과정은 일반적인 CNN과 동일합니다. (padding, stride, pooling 등의 테크닉적인 부분은 다른점이 없어서 생략하였습니다) 해당 논문에서는 charCNN을 도입함으로써 가장 최소 단위인 문자를 다루었다는 점과 좋은 성능을 보여주는 것이 학술적 연구에 기여한 부분입니다.
Very Deep Convolutional Networks for Text Classification
Very Deep Convolutional Neural Network(이하 VDCNN)은 charCNN이후에 더 깊은 층을 통해 성능을 개선한 모델입니다. charCNN의 장점을 그대로 가지며, convolutional block을 추가하여 더 깊지만 더 높은 성능을 보여줍니다.
VDCNN의 전체적인 구조는 quantized matrix가 convolutional block을 통과해 pooling과정을 거쳐 고정된 input값을 가지게 되고, 최종적으로 k-max pooling으로 중요한 특징점만 뽑아주게 됩니다. 그 이후에는 fully connected layer를 거쳐 최적화해주게 됩니다.

[그림2]VDCNN논문에서 사용된 모델의 시각화
VDCNN에서도 charCNN에서와 같이 정해진 문자를 고정된 글자 수에 quantization하는 과정을 거칩니다. 논문에서는 look-up table로 표현하였습니다. 그림에서 검은 박스를 의미합니다. (같은 말입니다)
그림에서 빨간 박스와 같이 Convolutional block은 2개의 순차적 convolutional layers를 의미합니다. 이는 Batch normalization과 activation function(ReLU)를 통과하게 됩니다. 특히나 kernel size를 3으로 고정시켜 temporal convolutional layer에 대한 정보 손실을 최소화할 수 있게 해줍니다.

[그림3]VDCNN논문에서 사용된 convolutional block의 이미지
빨간 박스와 같이 Convolutional block이후에 pooling을 통해 차원 수를 고정시켜 줍니다. 이를 통해 최초의 텍스트로부터의 input size를 고정시켜, 다음 convolutional block에 높은 수준의 정보 전달이 가능해지게 됩니다.
마지막으로, 노란색 박스에 해당하는 내용입니다. 논문상에는 3가지의 pooling에 대해 소개하였는데, k-max pooling의 성능이 가장 좋았습니다. 특히 K-max pooling의 경우 k개의 가장 중요한 특징점을 뽑는 장점이 있습니다.
결국 VDCNN은 ResNet에서의 residual block과 identity block과 같은 convolutional block, optional shortcut을 이용해 degradation을 감소시키는 데 도움을 줍니다. 참고로 convolutional block에서 batch normalization이 사용되어 dropout은 사용하지 않았습니다.
이를 통해 기존의 charCNN은 6개의 convolutional layers보다 더 깊은 29개의 convolutional layers를 통해 더 적은 오차율을 보여주게 됩니다. 그리고 깊은 층일수록 더 많은 데이터를 사용할수록 더 좋은 성능을 보이고 있습니다.
[처음부터 시작하는 머신러닝]
96%의 정확도를 보이는 character-level CNN을 통해 준실시간으로 왓챠(앱)에 생성되는 부적절 텍스트를 자동으로 분류하는 프로젝트의 과정들을 공유 하려고 합니다. 도움이 될 수 있기를 바라겠습니다.
1. 첫번째 삽질
데이터셋을 구성하는 부분이 가장 난해한 부분이었습니다. 학술적 연구, 케글과 같은 문제들은 이미 데이터가 풍부하고(대략 1M 데이터 셋), 문제가 잘 정의되어 있습니다. 연구원이 고민할 부분은 어떻게 하면 더 나은 알고리즘을 만들까이지, 어떻게 하면 문제를 잘 해결할 데이터를 구성할지는 아니었습니다.
저는 우선적으로 왓챠(앱) 내에서 신고된 텍스트와 임의의 텍스트를 바탕으로 데이터를 구축하기 시작했습니다. 신고받은 텍스트의 경우 전혀 문제가 없는 경우도 상당히 많아서 텍스트를 하나하나 읽어가며 레이블링 해주기 시작했습니다. 이진분류 문제로, 총 7천 개의 데이터 중 5천 개의 적절, 2천 개의 부적절 데이터를 확보할 수 있었습니다.

학습데이터 예시
그리고 대략 200만 개의 풍부한 왓챠(앱)의 텍스트를 바탕으로 word2vec을 이용해 언어모델을 만들었습니다. word representation이 잘 학습되었는지는 “왕-여왕 문제” 및 반의어 / 동의어를 통해 학습이 잘 되었는지 확인해 줄 수 있습니다. word2vec은 한 개의 단어를 임베딩 공간에서 표현한 것이기 때문에 [“어떤 것도 쉽게…”] 와 같은 텍스트는 [“어떤”], [“것도”], [“쉽게”] 각각을 word embedding에서 추출한 벡터를 더하여 해당 텍스트의 임베딩 공간에서의 위치를 얻을 수 있게 됩니다.
벡터화된 input을 가지고 Logistic regression, SVM, deep neural network 등을 통해 모델링을 진행하였습니다.
+-----------+----------+----------+----------+----------+ | | logistic | SVM | DNN | Ensemble | +-----------+----------+----------+----------+----------+ | acc | 0.8996 | 0.8958 | 0.9322 | 0.9364 | | recall | 0.8629 | 0.8534 | 0.8274 | 0.8345 | | precision | 0.8961 | 0.8806 | 0.8947 | 0.8999 | +-----------+----------+----------+----------+----------+
결과는 여러 분류기를 섞은 앙상블 모델(ensemble model)이 가장 좋았고, 대략 93%의 정확도를 보였습니다. 앙상블 모델은 soft voting해주었습니다.
문제는 실제 CS팀에서 사용할 만한 수준에 전혀 미치지 못했다는 것이었습니다. 부적절이라 판단한 텍스트를 읽어보면 10개중 2~3개만 부적절한 텍스트였습니다. 원인은 imbalanced data이다 보니 실제 부적절한 텍스트를 잘 찾지못해도 validation score에 큰 영향을 주지 않았습니다. 다시 말하면, 평가용 레이블 2,000개 중 부적절 레이블 400개를 전부 틀려도 정확도 80%가 나오는 것이 문제였습니다.
처참한 결과에 고통받던 중 참고자료를 하나 찾을 수 있었습니다. 넥슨에서 발표한 딥러닝 욕설탐지기를 참조하여 뭐가 문제일지 하나하나 살펴 봤습니다.
2. 두번째 삽질
넥슨에서는 금칙어 기반 분류기, charCNN, VDCNN 3가지를 바탕으로 동일한 주제에 대해 실험했습니다. 이에 영감을 받아 charCNN을 재생산(reproduction) 해보았습니다. 영어 이외 특수문자로 된 70개 문자에 한글을 추가했고, 불필요해 보이는 일부 특수문자를 제거해 90개 문자로 양자화(quantization) 했습니다.
문제는 7천 개의 데이터셋에 charCNN을 학습시킨 결과, 학습 정확도(training accuracy)도 향상되지 않지만, 검증 정확도(validation accuracy)가 0.7868로 고정되는 점이었습니다. 0.7868이 의미하는 바는 바로 데이터 셋의 정답 비율이었습니다. 바꿔 말하면, 정답 비율이 높은 걸로 무조건 답을 찍는 게 학습하는 것보다 점수가 높은 걸 모델이 학습해 버렸습니다.
Parameters도 줄여보고, quantization size도 줄여가면서 무엇이 문제인지 판단해야 했습니다. 추측건대 상당히 과적합(overfitting)되었기 때문에 데이터 셋을 늘리고, 모델을 얕게 만들어야 하지 않을까하는 가설을 세웠습니다.
MNIST 손글씨 예제를 여러가지 모델로 실험하던 중 이와 비슷한 경우가 있었는데, 지나치게 깊은 계층을 사용하였을 때입니다. 깊은 계층으로 인해 수렴하지 못한다면, 반대로 동일한 깊이일 때 적은 데이터일 때도 수렴하기 힘들다고 결론내릴수 있습니다.
이를 증명하기 위해 동일한 모델에 논문에서 사용되었던 예시인 AG’s news의 데이터셋을 7천 개로 강제로 줄여서 학습시켰더니 동일한 현상이 나왔습니다. 그럼 다시 최소 얼마의 데이터에 수렴하는지를 판단하기 위해 데이터 사이즈를 조금씩 늘리면서 학습시킨 결과, 최소 3만 개의 데이터는 있어야 동일 모델에서 수렴하는 것을 확인할 수 있었습니다.
👆 이 부분은 대략 1년 전 내용인데 재현하지 못해서 풀어서 이야기했습니다. 지금은 어떻게 해도 학습이 잘 되더라구요. 이렇게 기록이 중요합니다 😭
최소 3만 개의 데이터를 목표로 한땀한땀 레이블링 작업을 하다보니 어느덧 11만 개의 데이터셋을 확보할 수 있었습니다. 이때 많은 분들이 함께 작업을 도와주셨습니다. 8만 개의 학습데이터와 2만 개의 평가용 데이터, 그리고 테스트 데이터 1만 개를 준비하였습니다. 클래스는 7:3의 비율을 가지고 있습니다. 이를 바탕으로 새롭게 모델링을 시작했습니다.
3. 삽질의 결과
이전보다 훨씬 풍부해진 데이터를 바탕으로 모델은 슬슬 좋은 결과를 보여주기 시작했습니다. 나아가 “ᶠᵤᶜᵏ” 과 같은 특수기호는 sparse 혹은 차원의 저주(curse of dimensionality) 라고 불리는 문제가 발생하여 quantization에 제외했습니다. 특수기호에 대해서는 규칙기반으로 대처하는 것이 훨씬 효율적이고 효과적인 결과를 보였습니다.
이외에 문맥상 전혀 부적절한 표현에 영향을 주지 않는 “?”, “/“ 같은 특수기호들도 무시하도록 했습니다. 그리고 논문상에 언급된 input size를 1014 에서 512로 줄였습니다. 논문에서도 나온 내용이지만 1014개의 글자 수만으로 문서(documents)를 분류하는데 충분했습니다. 그리고 왓챠(앱)의 텍스트 특성상 장문으로 작성된 텍스트보다 짧은 몇 문장의 텍스트에 부적절한 표현이 빈번히 출현하여, 문자수는 512로 줄여도 충분히 좋은 성능을 보이면서 더 잘 수렴하였습니다.

[quantization 예시]
VDCNN같은 경우 charCNN의 후속모델이자 훨씬 깊은 layer를 사용하기 때문에 더 좋은 성능을 보이는 것으로 나왔습니다. 하지만 11만개의 데이터로는 VDCNN보다 charCNN이 더 최적화된 결과를 보였습니다. 해당 데이터로 이미 charCNN도 약간의 과적합된 결과를 보여주었습니다.
VDCNN의 장점은 깊은 계층을 이용하다보니 AG’s news같은 200K 부터 4M 데이터에서 좋은 성능을 보이는 scalability의 특징이 있습니다. 때문에 미래에 추가로 수집된 데이터를 바탕으로 최적화할 경우 VDCNN이 charCNN보다 더 나은 성능을 보여줄 여지가 충분합니다.
인공신경망(neural network) 관련논문들을 보면 해당 문제에 상당히 잘 튜닝된 평가 점수들로 소개되고 있습니다. 바꿔 말하면, 다른 도메인에서는 논문에서 언급된 만큼의 성능이 나오지 않을 수 있습니다.
tip!
Batch Normalization과 dropout을 동시에 사용하지 않길 권장드립니다.
왜냐하면 너무 많은 정보손실이 일어나기 때문입니다.
ResNet, VDCNN 둘다 batch norm을 사용해서 dropout은 사용하지 않았습니다.
최종적으로 11만 개의 텍스트 데이터와 charCNN모델을 바탕으로, 96%의 정확도를 보이는 부적절 텍스트 자동화 시스템을 구축할수 있었습니다.
+-----------+----------+-----------+----------+ | | Ensemble | charCNN | VDCNN | +-----------+----------+-----------+----------+ | acc | 0.9223 | 0.9638 | 0.9774 | | recall | 0.8196 | 0.9215 | 0.6702 | | precision | 0.8832 | 0.9513 | 0.8303 | +-----------+----------+-----------+----------+
아래의 예시가 금칙어 기반, word embedding으론 처리하기 힘들었던 부적절한 표현들을 잘 분류하는걸 확인할수 있었습니다.
[예시1]
잘 만들었는데 ^^ㅣ발 ㅈ같음
[예시2]
배두나 연기 오졌다. '간통죄로 콩밥먹었으면 내 배가 벌써 콩밥이야 씨 ㅂㅏㅏㄹ!!!'
추가적으로 charCNN의 ensemble 모델은 특별히 성능적 우위를 보이지 않아, 단일 모델만 사용하였습니다.
그리고 word embedding based model에서 character level CNN으로 변경되며 특히나 큰 이점을 보인 부분이 메모리의 효율성이었습니다. word embedding은 학습 시 사용된 모든 unique word(18만개)를 기억해야 해서 대략 2.7GB의 많은 용량에, 높은 메모리 점유율을 보였습니다. 반면에 character level CNN의 경우 신경망의 parameters만 기억하면 되어 메모리 효율이 높았습니다.
4. 드디어 성공
최종적으로 character-level CNN이 준 실시간으로 유저들이 작성하는 텍스트 중 부적절 여부를 판단하고 있습니다. 이에 해당되는 텍스트는 CS팀에서 최종적으로 확인할 수 있는 자동화 프로세스가 도입되었습니다.
그리고 적극적인 구글링을 통해 참고자료를 확보해 나가는 것이 중요합니다. 특히나 데이터셋은 얼마만큼이 충분한지, 내가 만든 모델의 성능은 충분히 뛰어난지, 검증점수(validation score) 기준으로는 좋지만 실제 비지니스 수준에서 유의미하게 사용할 수 있는지 등등입니다. 결국 뛰어난 알고리즘도 중요하지만, 이보다 실제 제품에 잘 녹이는 것이 제일 중요하다고 생각합니다. 추가적으로 96%의 정확도라 하였지만, 도메인, 모델에 따라 체감되는 성능은 얼마든지 달라질 수 있음 을 염두에 두어야 합니다.
[마무리]
이제는 더이상 CS팀에서 하나하나 금칙어를 검색하고, 읽어보는 수고를 하지 않아도 됐습니다. 그리고 무엇보다 왓챠(앱) 유저들에게 조금은 더 깨끗해진 코멘트를 보여줄 수 있게 됐습니다.
앞으로의 개선방안도 여전히 많이 남아 있습니다. 레이블링 작업에 공수가 상당히 많이 들어갔는데, 이를 weakly supervised learning을 통해서 앞으로의 문제에 대해서 좀더 효율적으로 리소스를 관리할 수도 있습니다. 또한 character aware language model을 만들어 다용도의 자연어처리를 수행할 수 있습니다. 최근 SOTA(state of the art)를 갱신하고 있는 BERT, 혹은 XLNet을 활용하는 방법도 있습니다. 추가적으로 CNN에서 좋은 성능을 보여주는 EfficientNet과 같이 이미지처리를 해주는 테크닉들을 이용한다면 충분히 좋은 논문주제로 발전시킬 수도 있습니다.
왓챠 R&D팀에서는 tensor factorization, graph neural network, deep reinforcement learning등 다양한 문제와 방법들을 연구 개발중에 있습니다. 함께 고민하고 문제를 해결하고 싶으신 분들은 채용공고 로 지원해 주시면 됩니다.
감사합니다.
 가입하기
가입하기