목차
1. 개요
2. 원하는 결과
3. 시나리오
4. 내부작동방식
5. 분석 결과
6. 한계 및 향후 계획
1. 개요
과제명 : 스토리체인(Dapp 프로젝트)의 생태계 안정성을 ABMS 시뮬레이션을 통해서 검증
과제기간 : 2018.11월1일 ~ 12월31일까지
소기과업 : 2년 동안의 보상풀 변동성을 파악하여서 토큰 유동 정책에 활용
시뮬레이션환경 :
- 사용툴 : Repast Symphony 2.6
- OS : MacOS 10.13.6, Window 10
2. 원하는 결과
시뮬레이션을 통해서 다음과 같은 결과를 확인해보자 했다.
첫째, 급격하게 토큰을 변동시키는 지점 찾기
둘째, 특정 참여자에게 토큰이 쏠리는 배분 정책 찾기
셋째, 시간이 지날수록 EcoPool 에서 보상해주는 것을 줄이고 PD 가 투자하는 비율을 높인다
3. 시나리오
참여객체 : ST(작가), PD(제작자), RD(독자), Story(스토리)
주요시나리오(관계형성)
1) 위 4 객체는 Story 를 통해서면 관계가 형성된다.
2) 공동 작업일 경우에만 ST 와 ST 가 연결된다(현재 코드는 2인 공동 작업만 가능)
3) ST 가 Story를 만들었을 때 관계형성됨(최대 10개까지 Story 창작 가능)
4) ST 의 Story 타이핑 양이 일정 수 이상이면 해당 지표의 수치가 올라간다
5) ST 가 Story 에 새로운 신(Scene)을 만들면 해당 지표의 수치가 올라간다
6) PD 가 Story에 투자했을때 관계형성됨, 투자는 PD의 욕구 범위에 Story의 제품특성이 들어와야 이뤄짐.
7) PD 는 Story 이 검증에 참여하면 해당 Story 에 검증 수치가 올라간다
8) PD 가 Story 의 branching에 참여하맨 Story 에 branch 수치가 올라간다
9) RD 가 Story에 반응했을때 관계형성됨, 반응은 RD의 욕구 범위에 Story의 제품특성이 들어와야 이뤄짐
10) RD 가 Story 을 읽었으면 해당 수치가 올리간다
11) RD 가 Story 의 공유하면 해당 수치가 올라긴다
4. 내부 작동 방식
객체들이 어떻게 설계되어 있는지 클래스 다이어그램으로 먼저 설명하고, 내부 로직중에 설명이 필요한 부분만을 간추려서 설명하고자 한다.
4.1 클래스 다이어그램

초기화 클래스
Parameters
초기 설정값을 관리하는 클래스
SimulationBuilder
ABMS 시뮬레이션 메인 클래스로서 다른 클래스 모두를 여기서 초기화한다.
EntreNetworkGenerator
Agent 간 관계 설정을 총괄하는 클래스로서 Parameter 에서 설정한 조건에 따라서 해당하는 클래스를 호출한다.
AdjacentNetworkGenerator
Agent 간 관계를 인접한 노드에서 찾아서 연결해주는 클래스이다
RandomNetworkGenerator
Agent 간 관계를 설정할때 랜덤으로 선택된 agent 를 선택해서 연결한다
BarabasiAlbertNetworkGenerator
Agent 간 관계를 설정할때 agent 의 클러스터가 더 큰 것을 선택해서 연결한다.(배경이 좋은 것을 선택)

주요 객체의 클래스
Agent
주요 객체의 상위 객체로서 공통적인 기능을 가지고 있다
PD
제작자 객체로서 스토리의 투자와 검증을 하는 역할 한다.
RD
독자 객체로서 스토리에 호응을 하는 역할을 가지고 있다
ST
작가 객체로서 스토리를 생성하고 공동 작업을 한다.
Story
Agent 간의 중심 역할을 하는 객체로서 Story 객체를 통해서 다른 객체들이 연결된다.
GrowthSchedule
Story 성장지수( GI ) 을 평가하는 클래스로서 독립적인 스케줄로 작동한다.
4.2 주요 작동 방식
Repast Symphony 는 Agent 기반의 시뮬레이션 툴이다. 시뮬레이션 원하는 객체(Agent)들을 설정하고 독립적인 스케줄을 할당한다. 코드에서 각 객체(Agent)에 스케줄을 할당하는 부분은 SimulBuilder 클래스에 아래 부분과 같이 구현되어 있다.
public void scheduleActions() {
ISchedule schedule =
repast.simphony.engine.environment.RunEnvironment.getInstance().getCurrentSchedule();
ScheduleParameters parameters = ScheduleParameters.createRepeating(10,Parameters.adaptationSpeed+3, 9);
schedule.scheduleIterable(parameters, pdList, “doPDaction”, true);
// call PD schedule
parameters = ScheduleParameters.createRepeating(2,Parameters.adaptationSpeed+17, 8);
schedule.scheduleIterable(parameters, stList, “doSTaction”, true);
// call ST schedule
parameters =
ScheduleParameters.createRepeating(2, Parameters.adaptationSpeed+9, 8);
schedule.scheduleIterable(parameters, rdList, “doRDaction”, true);
// call RD schedule
}
SimulBuidler.java
Schedule 이란 독립적으로 정해진 조건에 따라서 지속적으로 호출되는 함수이다. 호출 조건은 Interval(간격), Priority(우선순위), Start(시작시점) 을 설정한다. 위 코드에서는 parameters 에서 초기조건 설정 후 schedule 에게 전달한다. 각 Agent 의 스케줄이 지속적으로 돌면서 객체가 데이터를 만들어낸다. 우리의 관심은 토큰 데이터이므로 2년 정도의 가동(Tick)을 가정하고 데이터를 수집한다.
5. 분석 결과
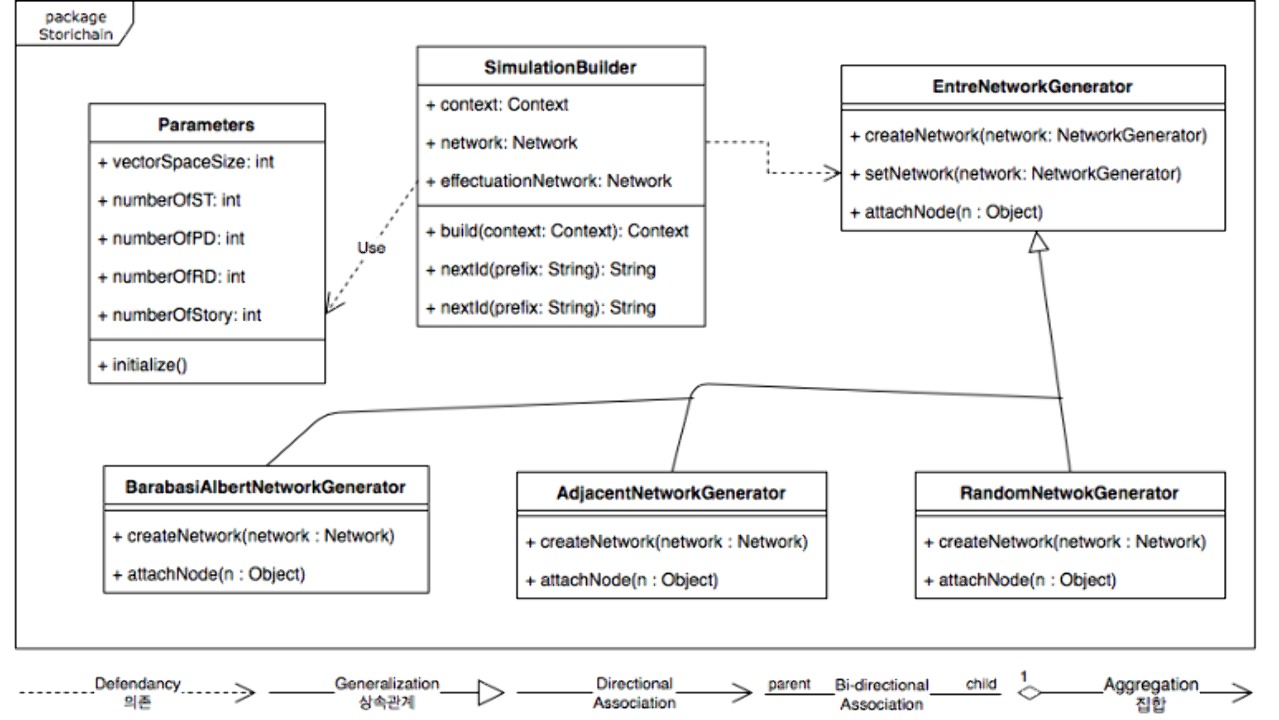
Agent(PD,ST,RD,Story)의 활동 화면
Agent(PD, ST, RD, Story)들이 어떻게 활동하는지 그림으로 보여주고 있다. 파란색 원형은 PD을 나타낸다. 주황색 정사각형은 RD을 나타낸다. 연두색 스타형은 ST 작가를 나타낸다. 마지막은 하늘색 십자는 Story 를 나타낸다. 현재 위 캡처화면은 1,400 Ticks 가 지난 이후의 그림으로 ST(60), RD(166), PD(45),Story(106) 개씩 생성되었다.

Tick Count 1,400 에 도달 시에 2년이 지났다고 설정했다
초기 EcoPool 은 1,000 token 으로 설정했다.
2년이 지났을 때 대략 0.5 배 정도 토큰 인플레이션이 발생했다.
원했던 결과와 대조해보자.
첫째, 급격하게 토큰을 변동시키는 지점 찾기
=> 550 Tick count 이후에 작가(ST)가 피디(PD)보다 토큰 수혜율이 눈에 띄게 증가한다. 현재는 공동 작가 수만큼 인플레이션을 발생 시켜서 그런 것으로 보인다.
둘째, 특정 참여자에게 토큰이 쏠리는 배분 정책 찾기
=> 우와 같다. 1,300 Tick 이후에 PD 의 토큰이 서서히 감소함을 보인다. 투자보다 보상이 적다는 의미인데 더 길게 지켜봐야 확신한 의미를 알 수 있을 것이다.
셋째, 시간이 지날수록 EcoPool 에서 보상해주는 것을 줄이고 PD 가 투자하는 비율을 높인다
=> 시간이나 agent가 증가하는 수에 따라서 토큰 인플레이션을 낮게 조정하는 작업이 필요하다.

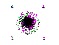
Total Token Circulation in App
가로는 Tick count 이며, 세로는 총 토큰량을 나태낸다. 수식은 3차식 추세선을 나타낸다. 빨간 추세선이 99% 반영함을 보인다.

PD token
가로는 Tick count 이며, 세로는 PD의 총 토큰량을 나태낸다. 수식은 3차식 추세선을 나타낸다. 빨간 추세선이 97% 반영함을 보인다.
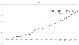
ST Token
가로는 Tick count 이며, 세로는 ST의 총 토큰량을 나태낸다. 수식은 3차식 추세선을 나타낸다. 빨간 추세선이 98% 반영함을 보인다.
6. 한계점 및 향후 계획
주요 한계점은 관계중심의 원인을 파악하고자 주로 사용하는 네트워크 이론을 객체 간에 적용할 수 없었다. 그래프를 통해서 사회과학, 컴퓨터공학에서 주로 사용하는 관계형성모델인 네트워크 이론은 객체 간의 차이가 없는 1대1 의 관계를 가정한다. 하지만, 본 연구에서는 객체 간의 특징이 다르므로 연결 중심성, 고유벡터 중심성, 매개 중심성, 조화 중심성, 근접 중심성 같은 네트워크 이론을 그대로 적용할 수 없었다.
토큰 시뮬레이션을 통해서 향후 추세를 파악할 수 있다. 또한, 토큰 추세 분석을 통해서 원하는 추세 방향을 만들어 낼 수도있다. 하지만, 주요 보상 비율을(GrowthIndex) 가중치 고려없이 단순하게 설정해 놓아서 실제 만들어진 DApp하고의 차이를 어떻게 줄일지 고민이 필요하다. 향후에는 Dapp 을 개발하면서 주요 토큰 정책들을 ABMS 시뮬레이션 모델에 상세히 반영하므로써 실제 Dapp과 시뮬레이션의 오차를 줄이고자 한다. 오차를 줄이므로써 토큰 유동 정책을 예측하면서 실행할 수 있을 것이다. 앞으로 시뮬레이션의 변동 부분을 본 페이지를 통해서 지속적으로 업데이트 할 것이다.
<시뮬레이션 소스 위치>
storichain/AbmsSimulation Adaptable agent simulation. Contribute to storichain/AbmsSimulation development by creating an account on GitHub.github.com
공개비화: 부족한 면이 많아 공개를 망설이다. 본 프로젝트는 지속적으로 진화하고 있다는 것을 보여주고자 최종 공개를 결정했습니다. 곧 더욱 진보된 결과를 약속하며 많은 의견을 기다립니다.
 가입하기
가입하기