이제 머신 러닝이 무엇인지 기술적인 이야기를 시작하겠습니다.
1. 머신 러닝의 개념
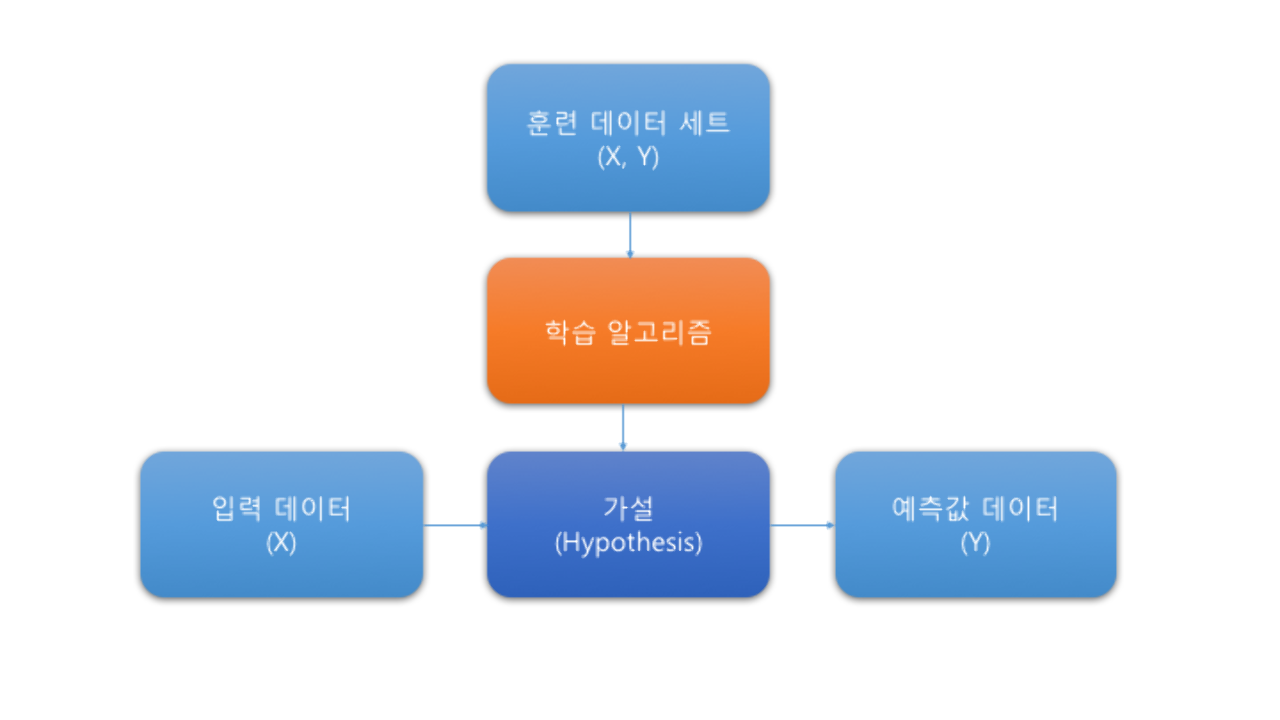
머신 러닝의 개념도
위 그림은 머신 러닝의 개념도 입니다.
.
스팸 메일 분류기로 설명을 합니다. (만능 예시 이므로 기억해두세요!)
메일이 스팸인지 아닌지 판별하는 머신을 만든다고 하면
.
훈련 데이터 세트
(X,Y) = (메일 내용, 스팸 여부)
입력 데이터
X = 새로운 메일 내용
예측값 데이터
Y = 스팸 여부
위와 같이 표현될 것입니다.
.
그리고 우리의 머신 러닝 알고리즘은 입력값에 대한 예측값의 정확성을 높이기 위해 열심히 학습하여 가설을 제공할 것입니다.
다양한 학습 알고리즘이 있고 다양한 가설이 존재할 수 있지만 그 가설은 결국 하나의 방정식이라고 생각할 수 있습니다.
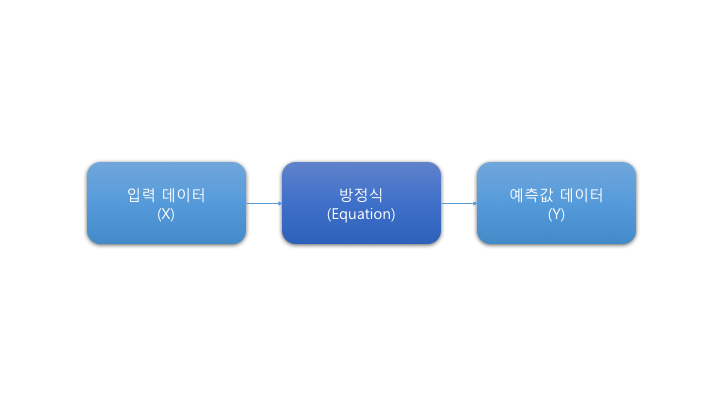
방정식의 개념도
고등학교 때 부터 보아왔던 방정식에 학습이라는 개념을 얹은 것이 머신 러닝입니다.
정확하게 맞는 말은 아니지만 머신 러닝을 처음 접하시는 분들의 막연한 두려움(?)이 줄어들기를 바라며 이제 학습을 어떻게 하는지 알아보겠습니다.
2. 머신 러닝에서 학습
.
학습 알고리즘은 어떻게 만들까요?
이 단계는 인간의 사고 과정을 그대로 따라 갑니다.
만약 사람이 어떤 데이터를 토대로 결과를 예측했는데 틀렸다면 무엇이 틀렸는지 확인하고 결과가 올바르게 나타나는 방향으로 수정할 것입니다.
머신 러닝을 예측의 틀린 정도를 오차(Error)로 생각하고 올바른 결과가 나오도록 방정식을 수정합니다.
.
오차를 수정하는 방식에는
최소제곱법(method of least squares — LSM or LMS)
최우추정법(maximum likelihood method — MLE)
최대사후확률추정(maximum a posterior estimation — MAP)
기울기 하강법(gradient descent — GD)
역전파(backpropagation — BP)
등등
매우 매우 많습니다.(약자로 많이 사용하니 눈에 익혀두세요!)
.
각각의 방식은 하고자 하는 작업의 성격에 따라서 다르게 사용합니다.
그럼 머신 러닝으로 할 수 있는 작업을 먼저 알아보고 어떻게 쓰이는지는 후에 직접 알고리즘을 보면서 생각하겠습니다.
.
3. 머신 러닝으로 할 수 있는 것
.
머신 러닝으로 할 수 있는 작업은 크게 네가지 카테고리로 나뉩니다.
지도 학습, 비지도 학습, 준지도 학습, 강화 학습
(supervised, unsupervised, semi-supervised, reinforcement)
.
학습을 할 때 사전 지식이 있는 것은 지도 학습
맨 땅에서 데이터를 분석해 지식을 도출해 내는 것은 비지도 학습
지도와 비지도 학습을 동시에 실행하는 준지도 학습
행동에 대한 상과 벌을 적용해 지식을 키워가는 강화 학습
.
예를 들자면 앞서 설명한 스팸 메일 분류기는 지도 학습이고
아무런 기준 없이 데이터의 접근성을 확인해 분류하는 군집화(Clustering)가 비지도 학습입니다.
‘AlphaGo’와 같이 승패가 결정되는 게임에서 이기는 방향으로 학습하는 것이 강화 학습입니다.
.
머신 러닝의 큰 카테고리는 위와 같고
세부적인 카테고리는 아래 링크에서 참조하였습니다.
A Tour of Machine Learning Algorithms In this post, we take a tour of the most popular machine learning algorithms. It is useful to tour the main algorithms…machinelearningmastery.com
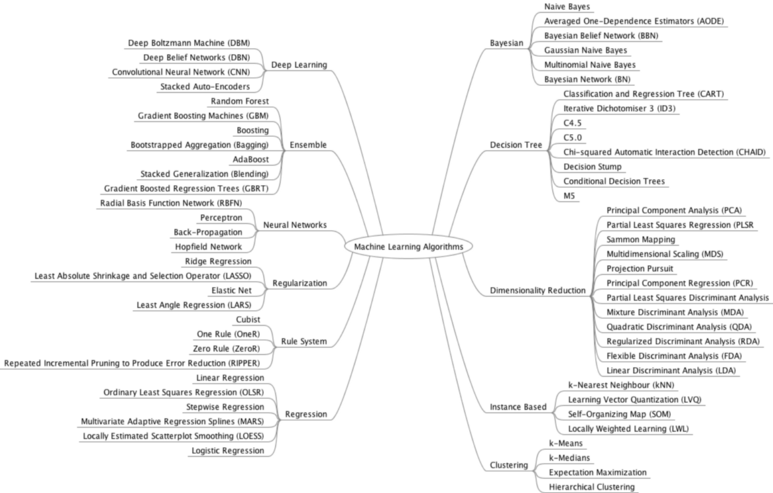
머신러닝 카테고리 분류
이 많은 것들을 여기서 모두 언급하지는 않겠습니다.
(배워볼게 정말 많네요…)
.
앞으로 가장 많이 쓰이는 네가지를 중심으로 스터디를 진행하고자 합니다.
분류, 회귀 분석, 인공신경망, 군집화
오늘은 간단하게 이것들에 대해 소개하는 시간을 갖도록 하겠습니다.
.
먼저 지도학습에서 분류와 회귀분석 그리고 인공신경망입니다.
.
분류(Classification)
여러 결과로 분류된 기존의 데이터를 토대로 새로 수집된 데이터가 어느 결과에 속하는가를 예측하는 가정을 세우는 것
스팸 분류기가 바로 분류에 속하는 것이지요.
.
회귀분석(Regression Analysis)
관찰된 연속형 변수들에 대해 두 변수 사이의 모형을 구한뒤 적합도를 측정해 내는 분석 방법
이것으로 미래에 발생할 일을 예측하는데 (과거 데이터로 봤을 때 이번달 실적은 어떨 것인가?) 사용합니다.
.
인공신경망(Artificial Neural Network)
뇌의 뉴런에서 아이디어를 착안한 것으로 시냅스의 결합으로 네트워크를 형성한 인공 뉴런이 학습을 통해 시냅스의 결합 세기를 변화시켜, 문제 해결 능력을 가지는 모델 전반을 나타냅니다. 말이 어렵게 쓰여있지만 뇌의 작용을 숫자(가중치)로 표현하는 것입니다. 인공신경망을 기반으로 설계된 딥러닝(Deep Learning)이 요즘 정말 핫한 분야이기도 합니다.
.
비지도학습에서는 군집화가 있습니다.
.
군집화(Clustering)
답이 주어지지 않은 데이터를 가지고 분석을 하고 분류합니다.
특징 벡터를 찾아내는데 사용합니다. 사람이 미처 발견하지 못하는 특징도 파악할 수 있기에 응용 범위가 넓은 방식입니다.
.
강화학습은 후에 따로 주제를 나누어서 스터디 해보도록 하겠습니다.
다음 시간 부터는 수식과 함께 각각 알고리즘이 어떻게 구성되는지 스터디 하겠습니다.
cf) 오탈자 혹은 잘못된 개념에 대한 피드백은 항상 환영합니다.
 가입하기
가입하기