이번 시간에는
1.
확률이라는 개념이 추가된
로지스틱 회귀를 알아보고
2.
지금까지의 분석이 올바른 것인지 검증하는 단계를 알아보겠습니다.
(매우 매우 중요합니다.)
.
로지스틱 회귀 (Logistic Regression)
.
먼저 로지스틱 회귀는 앞선 방식들과는 조금 성격이 다릅니다.
이는 선형 회귀 분석과는 다르게 결과가 범주형일 때 사용합니다.
(ex — 학생이 문제를 맞을 것인지 틀릴 것인지, 내일 비가 올지 안올지, 과목의 학점이 A인지 B인지 C인지)
.
y = w*x + b
꼴에서
y를 확률에 관한 식으로 만들고 이항하여 로지스틱 함수를 얻어냅니다.
.
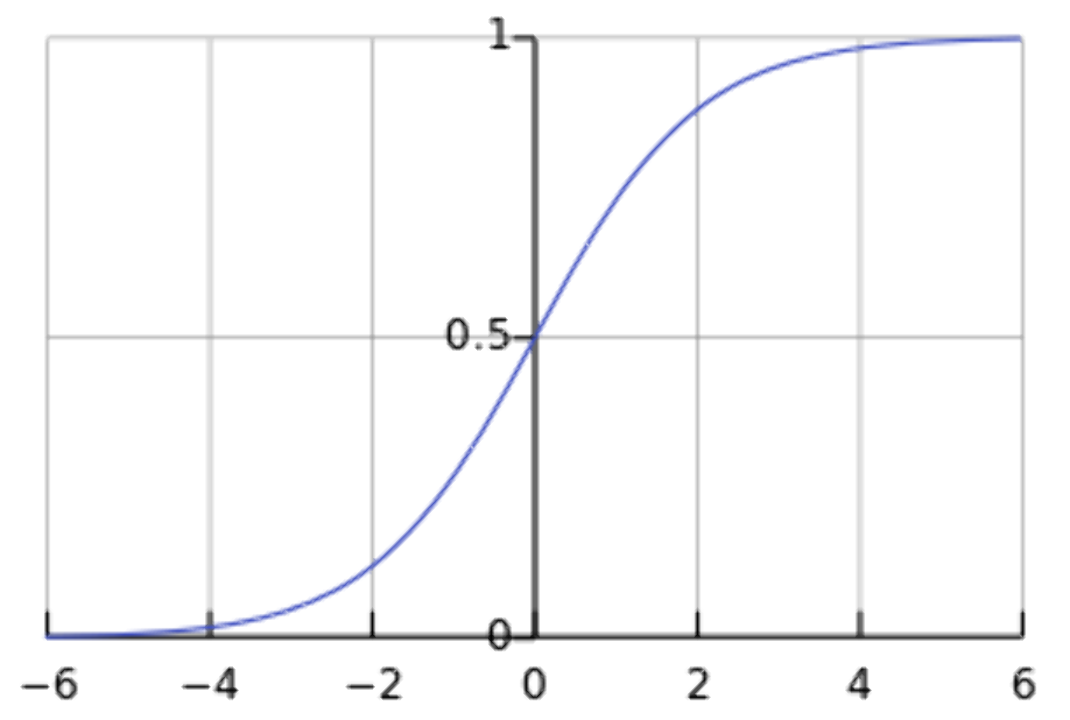
로지스틱 함수의 모양은 아래와 같이 표현됩니다.

로지스틱 함수의 형태

로지스틱 함수
x의 값이 증가하던 감소하던 무관하게 f(x)는 0과 1 사이의 값을 갖는 값이 됩니다.(확률로서 사용할 수 있는 것입니다.)
.
.
이제 로지스틱 함수를 어떻게 사용하는지 단계별로 생각해 보겠습니다.
.
먼저 결과값
y 를 odds 비율(성공확률/실패확률) 으로 생각합니다.
(y 범위 :0~ 무한대)

odds 비율 : 성공확률/실패확률
.
이 확률값은 계수들에 대해 비선형이기 때문에 선형으로 변환하기 위하여 자연로그를 취합니다. (y 범위 :-무한대 ~ 무한대)
(이 과정을 로짓 변환 (logit transformation)이라고 합니다.)

odd 비율을 로짓 변환
.
여기까지 진행하면 회귀 분석의 방정식을 아래와 같이 표현할 수 있습니다.

y = w *x 꼴이 이와 같이 표현되지요
.
그러면 우리는 성공 확률이 관심이 있는 것이므로 성공 확률 P에 대하여 이항을 해줍니다.

성공확률에 대한 식으로 이항 > 역 로지스틱 함수
.
이렇게 완성된 식으로 마찬가지로 학습하면
우리는 입력 데이터에 따른 결과의 확률을 알 수 있습니다.
.
.
.
이 로지스틱 회귀는 회귀 분석이지만 분류기의 성격을 가집니다.
.
Wikipedia에 따르면
로지스틱 회귀
.
이는 독립 변수의 선형 결합으로 종속 변수를 설명한다는 관점에서는 선형 회귀 분석과 유사하다.
하지만 로지스틱 회귀는 선형 회귀 분석과는 다르게 종속 변수가 범주형 데이터를 대상으로 하며 입력 데이터가 주어졌을 때 해당 데이터의 결과가 특정 분류로 나눠지기 때문에 일종의 분류 (classification) 기법으로도 볼 수 있다.
.
정체성이 혼란스러운 친구이지만 우리는 이것이 범주형(카테고리)으로 표현되는 결과를 얻고 싶을 때 쓴다는 것을 알면 됩니다.
.
.
지금까지 회귀 분석에 대해서 알아 보았는데 의문이 드는 것이 있을 것 입니다.
.
학습 결과가 맞는 지 어떻게 확인하죠??
.
열심히 모델을 만들어서 학습을 시켰는데 정답이 엉뚱하게 나온다면 아무런 쓸모가 없는 결과일 것입니다.(그리고 이런 일이 비일 비재 합니다.)
.
이것은 모델의 신뢰도 검증을 통해서 확인하고 올바르게 수정합니다.
.
모델의 신뢰도 검증
.
우리의 예측과 실제 결과가 어떤 오차를 갖는지를 확인하고 그것이 유의미한 데이터인지 판별하는 것입니다.
(학습은 이 오차를 줄여가는 것 이구요!)
.
이를 위해 보통 ROC Curve를 그리고 AUC (the Area Under a ROC Curve)로 판단합니다.
.
ROC Curve

ROC Curve
x축 : 틀린 것을 맞다고 할 확률
y축 : 맞은 것을 맞다고 할 확률
.
그래프를 보면 왼쪽 위(맞은 것은 맞다고 틀린 것은 틀리다고 할 확률)에 가까울 수록 좋은 모델입니다.
올바른 판단을 한다고 볼 수 있는 것이지요
.
그리고 왼쪽 위에 가까운 그래프라는 기준은 AUC 해석을 사용합니다.
ROC 곡선 아래 부분의 면적이 1에 가까울 수록 왼쪽 위에 근접한 그래프라는 것이지요.
.
.
그렇다면 이제 예시 코드입니다.
로지스틱 회귀로 모델을 만들고 AUC 해석으로 신뢰도를 확인하겠습니다.
(LogisticRegression.py > setting: python 3.5, tensorflow)
proauto/ML_Practice Contribute to ML_Practice development by creating an account on GitHub.github.com
데이터는
.
(x1 : 0~ 10) 비가 올 가능성
(x2 : 0 ~ 10) 온도
결과 : (y : 0 or 1) 눈이 올지 안올지
조건 : 비가 올 가능성이 5보다 크고 온도가 5보다 작을 때 눈이 온다.
랜덤으로 100개의 데이터 생성
.

x축 — x1 , y축 — x2, 파란색 — 눈이 온다
.
이렇게 구성하고 로지스틱 회귀를 사용해서 학습을 진행합니다.
(다른 부분은 같고 오차의 정의가 좀 다른데 코드에서주석을 달았습니다.)
.
그러면 예측값은 0~ 1 사이의 값으로 나타나고
그러면 이 값을 실제값과 비교하여 신뢰성을 검증합니다.(ROC , AUC)
.

학습에 따른 AUC값의 변화
.
Tensorflow에서는 ROC Curve를 통해 AUC 값을 제공하는 함수를 가지고 있으며우리는 AUC 해석을 통해서 비교를 할 수 있습니다.
(학습을 할수록 정확도가 증가하고 마지막에는 95%의 정확도를 보입니다.)
.
.
지금까지 우리는 회귀 분석을 통해서 우리가 알고자하는 모델의 방정식을 학습을 통해서 도출해낼 수 있게 되었습니다.
.
앞으로 진행할 부분도 이와 같은 사고를 계속 확장해나가는 것 이므로 이번 스터디가 중요하다고 생각합니다.
.
그럼 다음에는 로지스틱 회귀로 잠깐 맛을 봤던 분류(Classification)로 돌아오겠습니다.
cf) 오탈자 혹은 잘못된 개념에 대한 피드백은 항상 환영합니다.
 가입하기
가입하기