오늘은 분류에 대해서 알아보겠습니다.
.
분류(Classification)
.
분류는 말 그대로 입력이 어떤 카테고리에 해당하는지 나누는 것입니다.
.
스팸 문자인지, 눈이 올지 안올지, 학생의 학점이 A,B,C,D 중 어느 것인지 등등의 방식으로 사용할 수 있습니다.
.
로지스틱 회귀는 앞에서 알아보았으니 이번엔
.
KNN(K-Nearest Neighbors) 방식을 알아보겠습니다.
.
이 방식은 분류에서 사용하는 가장 단순한 종류의 알고리즘이라고 평가받는 방식입니다. (실제로 이론적으로 가장 간단합니다.)
.
입력값과 K개의 가까운 점들이 있다고 생각하고 그 점들이 어떤 라벨과 가장 비슷한지를 판단하는 것입니다.
비슷하다는 것의 정의는 역시 오차(거리)로 판단합니다.
.

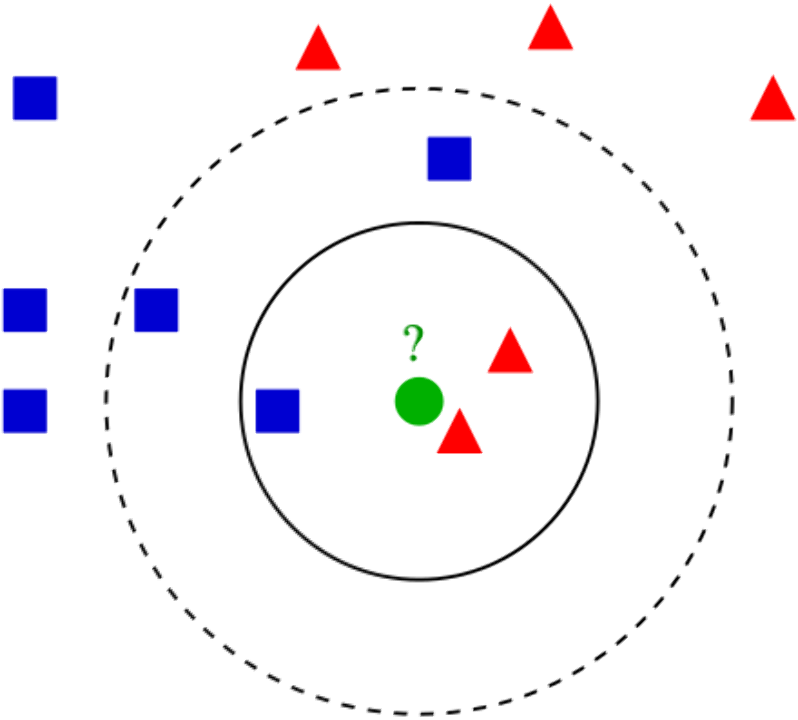
KNN — Wikipedia
초록색 점을 k = 3이라는 기준으로 바라보면(진한 원)
빨간색 삼각형과 더 비슷하다고 할 수 있으므로
(오차를 가중치로 두고 계산 — 일단 지금은 눈으로도 보입니다.)
초록색 입력은 ‘빨간 삼각형이다’ 라고 분류할 수 있습니다.
.
분류 기능을 강력하게 사용할 수 있는 MNIST 데이터를 사용하여 예시를 들겠습니다.

Mnist Data — http://yann.lecun.com/exdb/mnist/
.
이렇게 Mnist 데이터는 숫자 하나하나 라벨링 되어있는 28* 28의 이미지로 입니다.
.
55000개의 학습데이터와 5000개의 테스트 데이터를 제공합니다
(단비와 같은 데이터 입니다 ㅜ).
.

테스트 데이터 — 학습 데이터들과 비교한다.
K = 1 로 지정하면 가장 가까운 지점의 데이터를 정답으로 인지하는데 예제 코드를 돌려보면 (기존 데이터 5000개, 테스트 데이터 1000개)
89% 의 정확도를 나타냅니다.
.
(MNIST_KNN.py > setting: python 3.5, tensorflow,numpy)
proauto/ML_Practice ML_Practice -Python(with Tensorflow)github.com
.
이와 같은 분류에서 K를 늘리고 오차의 정도에 따라 판단 기준을 정하면 어느 정도 정확도가 향상 되겠지만 KNN은 한계가 명확한 알고리즘 입니다.
.
그 이유는
게으른 학습 +속도
이라고 할 수 있습니다.
.
KNN은 굉장히 게으른 알고리즘(lazy learning)입니다.
사실상 학습 이라기 보다는 학습 데이터를 가지고만 있지요.
보통 머신 러닝에서는 데이터를 가지고 학습을 하고 모델을 만드는 과정이 존재하는데
KNN은 이 부분이 생략된 분류 방법입니다.
.
그렇기에 KNN은 그냥 기준과의 단순 오차 비교이고 데이터가 많아지면 오래 걸리게 됩니다.(무한 노가다)

1000개 테스트하는데도 꽤 걸립니다…
.
그렇다면 우리는 어떤 방법으로 분류를 해야할까요??
.
앞서 배운 로지스틱 회귀를 사용해도 되고 딥러닝을 사용할 수도 있습니다.(처리하고자 하는 데이터에 따라서 다르겠죠?)
.
사실 TensorFlow 튜토리얼을 보면 Mnist의 데이터들을 로지스틱 회귀의 일반화된 형태인 Softmax 회귀를 사용해서 처리합니다.
.
(MNIST_LogisticRegression.py > setting: python 3.5, tensorflow,numpy)
proauto/ML_Practice ML_Practice -Python(with Tensorflow)github.com
.
KNN보다 엄청나게 빠른 속도로 계산이 끝나고 정확도도 92% 정도로 나오기에……데이터가 많고 진짜 인간의 힘으로는 못할 것 같은 상황을 맞이하게 되시면 KNN은 배경 지식으로 간직하시고 로지스틱 회귀or 딥러닝을 쓰면 됩니다.
.
결론이 좀 이상(?)하지만 분류에 대한 이야기를 마치고 다음 시간에는 인공신경망에 대한 이야기로 돌아오겠습니다.
.
cf) 오탈자 혹은 잘못된 개념에 대한 피드백은 항상 환영합니다.
 가입하기
가입하기