오늘은 비지도 학습인
군집화(Clustering)
에 대해서 스터디 하겠습니다.
.
.
일단 비지도 학습에 대해 언급한지 오래되었으므로 리뷰하자면
.
지도 학습은 데이터에 답이 정해져있고 그것을 학습하는 것이고
ex )0~9의 숫자
.
비지도 학습은 정해진 답은 없고 스스로 기준을 만들고 분류합니다.
.
예측을 하는 데 사용하기 보다는 데이터에서 의미를 파악하고 기준을 만드는데 사용합니다.
.
.
이러한 비지도 학습에서 가장 대표적인 것이 군집화(Clustering) 입니다.
.
군집화는 아무런 정보가 없는 상태에서 데이터를 분류하는 방법입니다.
.
이 중 가장 유명하고 간단한
K-means Clustering
을 예시로 살펴볼 것입니다.
.
그림으로 보는게 이해하기 쉽기에 섞어서 진행하겠습니다.
.
( Clustering.py > setting: python 3.5, tensorflow,numpy)
proauto/ML_Practice ML_Practice -Python(with Tensorflow)github.com
.
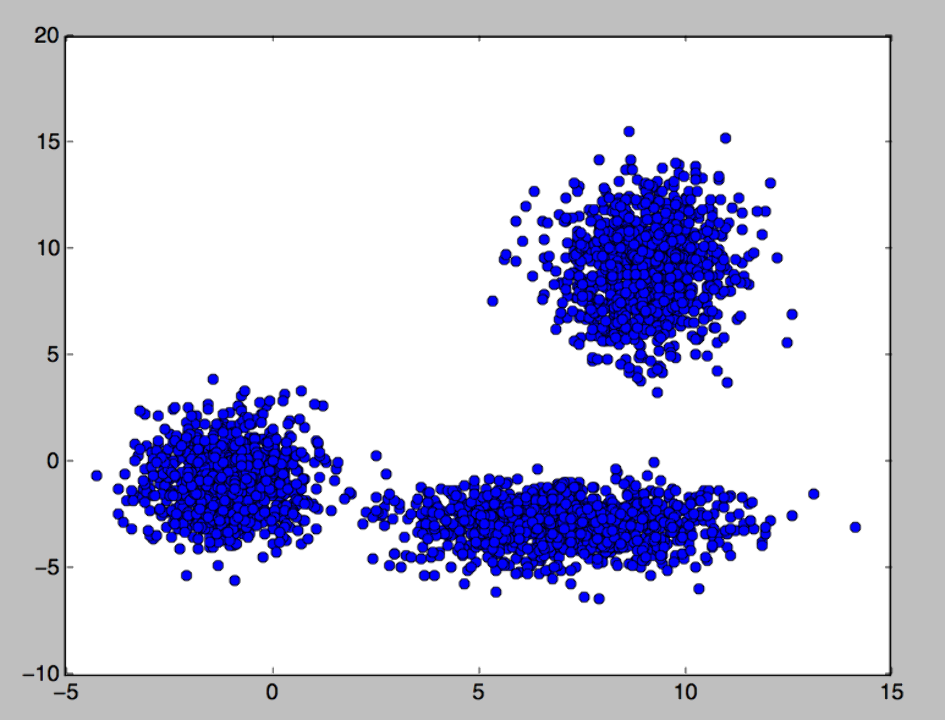
아래 데이터가 테스트 데이터 입니다.
(-1,-1), (9,9), (7,-3) 을 기준으로 정규분포를 따라 생성한 데이터
.
K-means Clustering이란 데이터 분류 종류를 K개 라고 했을 때
입력한 데이터 중 임의로 선택된 K 개의 기준과 각 점들의 거리를 오차로 생각하고
각각의 점들은 거리가 가장 가까운 기준에 해당한다고 생각하는 것입니다.
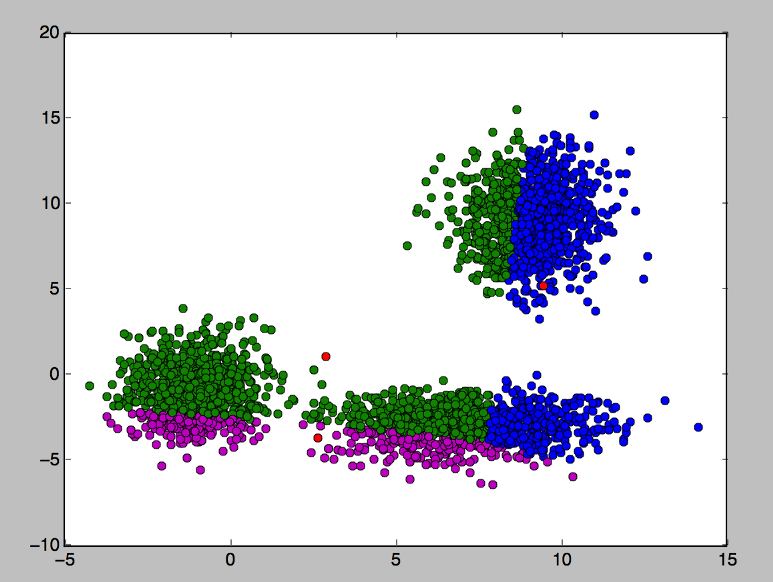
첫번째 학습
위 그림이 임의의 3개의 기준을 선택하고 주변 데이터들이 어떤 기준에 해당하는지 확인한 것입니다.
(빨간점 — 기준)
.
그리고 이제 각각 기준에 해당하는 점들 모두의평균을 새로운 기준으로 갱신하는 것입니다.
.
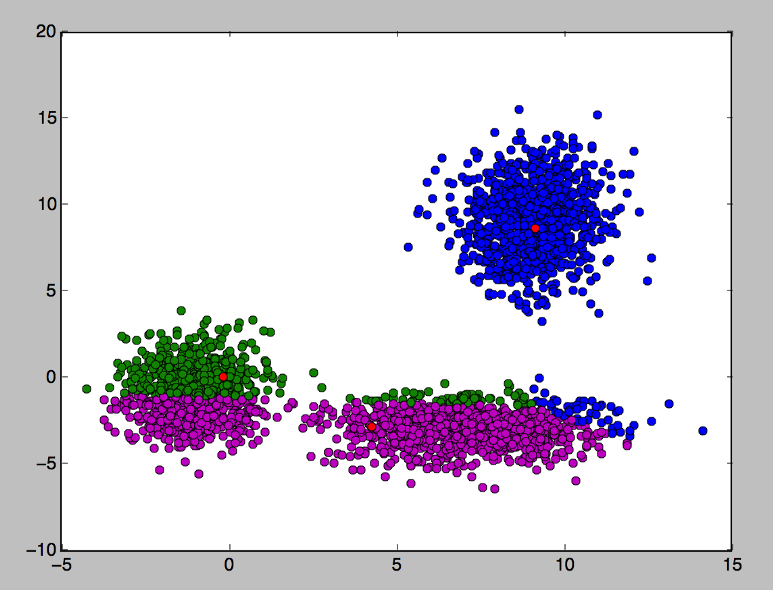
두번째 학습
.
가장 적절한 중심점들을 찾는 것이지요.
.
이렇게 학습을 반복하면
(사실 너무 쉽게 만든 데이터라서 3번 반복만에 끝났습니다…)
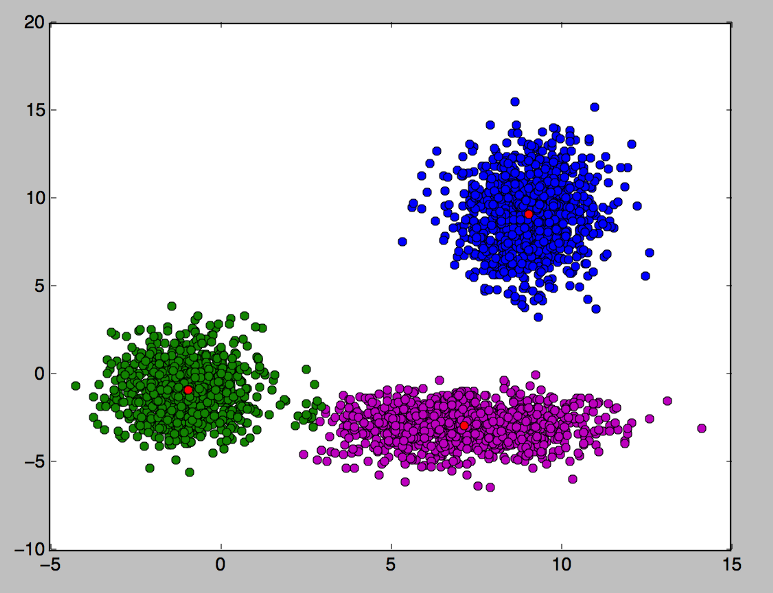
세번째 학습 — 깔끔하게 분류된 데이터들
위와 같이 깔끔하게 데이터를 분류할 수 있게 됩니다. .
.
이러한 군집화는 이미지 데이터 처리에 많이 쓰입니다.

Line Tracer Track
흰색과 검은색으로 확연히 구분된 사진에서 검은색 선을 찾아낼수있습니다.
(이는 모형차를 위한 차선으로 이를 이용해 차선을 유지해서 달리는 자율 주행 자동차(?)를 만들어 볼 수 있습니다.)
.
그리고 딥러닝의 획기적인 발전을 가져온 Pre-Training에도 사용됩니다.
지도학습인 딥러닝의 전처리 단계로 비지도 학습을 사용하는 것이지요.
.
데이터 처리에 군집화를 개별로 사용하는 것이 아니라 딥러닝과 함께 사용했을 때 엄청난 힘을 발휘한다는 것을 알게되면서 딥러닝이 지금처럼 활기를 띄게 됩니다.(Hinton 교수님의 발견)
.
이것으로 군집화에 대한 이야기를 마치겠습니다.
앞으로는 Deep Learning을 중심으로 하나하나 써보려 합니다.
다음에는 CNN(Convolution Neural Network)을 주제로 돌아오겠습니다.
.
cf) 오탈자 혹은 잘못된 개념에 대한 피드백은 항상 환영합니다.
 가입하기
가입하기