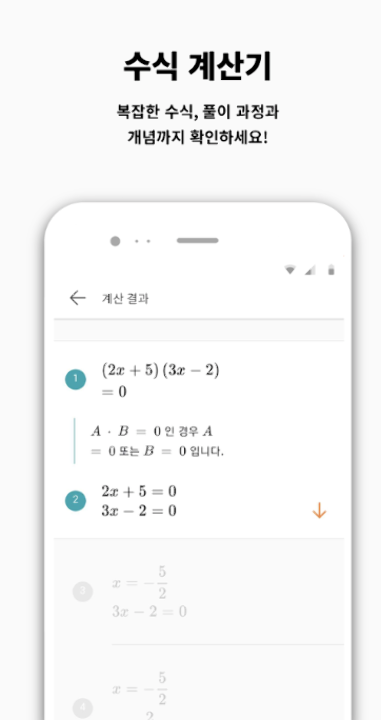
QANDA 애플리케이션은 문제 풀이 검색 서비스 뿐 만 아니라 수식이 찍힌 사진을 인식해 단계별로 풀이를 제공해주는 수식 풀이 서비스를 제공하여 많은 학생들의 궁금증을 해결해주고 있습니다. 수식 풀이 서비스는 유저가 풀이과정을 알고자 하는 수식을 사진으로 찍어 서버로 전송하면 자체 개발한 수식 인식 및 풀이 엔진을 통해 단계별 풀이과정을 유저에게 제공합니다.

QANDA 수식 풀이 서비스 예시
수식 풀이 서비스를 구축하는 데 기술적으로 어려웠던 부분은 수식 인식 엔진이었습니다. 수식 풀이 서비스의 성능이 얼마나 완벽하게 수식을 인식하는 지에 결정되기 때문입니다. 한 글자라도 잘못 인식하면 이상한 답을 내기 때문에 만족할만한 서비스를 만들기 위해서는 굉장히 높은 수식 인식률을 달성해야 했습니다. 매스프레소 개발팀은 딥러닝 오브젝트 디텍션 기술을 통해 인쇄물, 손글씨 상관없이 글자 하나하나를 성공적으로 인식할 수 있는 높은 인식률의 수식 인식 엔진을 만들었습니다.
이렇게 만들어진 수식 풀이 서비스는 성공적이었으나 내부적으로 유저 상호작용이 약하고 대기시간이 길다는 피드백이 있었습니다. 사진을 찍고 크롭 이후 서버에 전송하고 응답을 기다려야 했기에 대기시간이 길고 문제인식이 잘 안되는 경우에는 전 과정을 다시 반복해야 했습니다. 이러한 문제의 원인은 수식 인식 엔진이 서버에서 동작하기 때문에 서버에서 연산을 마쳐야만 유저에게 피드백을 줄 수 있다는 부분에 있었습니다. 이러한 문제를 해결하기 위해서는 수식 인식 엔진이 모바일에서 구동가능해야했습니다. 모바일에서 수식 인식 엔진이 구동 가능하면 유저가 찍은 사진에 대한 피드백을 즉각적으로 얻을 수 있고 사진 크롭과정을 유저가 하지 않아도 되었기에 서비스 플로우를 굉장히 단순화시킬 수 있기 때문입니다. 그래서 매스프레소 개발팀은 유저 상호작용을 강화시키고 문제 풀이 서비스의 프로세스를 간소화하기 위해 문제 인식 엔진을 모바일에서 구동 가능하게 만드는 딥러닝 최적화 프로젝트를 진행하기로 결정합니다.
본 글에서는 매스프레소 개발팀이 수식인식 딥러닝을 어떻게 모바일에 최적화시키고 실제 배포하였는 지에 대해서 공유하고자 합니다. 프로젝트를 진행하면서 오브젝트 디텍션 모델 모바일 최적화 관련 자료가 적어 많은 시행착오를 겪었습니다. 저희와 비슷한 문제에 직면한 분들께 이 블로그가 도움이 되었으면 좋겠습니다.
2. Mobile Deep Learning Optimization Process
수식 인식 딥러닝의 모바일 최적화는 크게 다음과 같은 과정으로 진행되었습니다.
- Base Architecture Selection 기존 수식 인식 네트워크 모델은 성능에만 초점이 맞춰져 개발되었기에 기존 모델의 연산량은 모바일에서 작동이 어려울 정도로 많습니다. 따라서 효율적인 연산량을 갖는 모델을 얻기 위해서 어떻게 딥러닝 모델을 최적화 하였는지 그 과정을 소개해드리고자 합니다.
- Float16/UInt8 Inference 딥러닝 연산에서 사용하는 대부분의 상수들은 일반적인 경우와 같이 32bit의 Float 자료형을 사용합니다. 최근에는 딥러닝 연산에 사용하는 상수 자료형을 압축시켜 16bit의 Half Float, 8bit의 Unsigned Integer로 트레이닝을 시도하여 획기적으로 모델 용량과 연산량을 줄이면서 성능저하를 최대한 막는 방법들이 보고되고 있습니다. 이러한 방법들에 대해 간단하게 리뷰하고 어떤 방법을 수식 인식 엔진에 적용했는지 소개해드리고자 합니다.
- Mobile Deep Learning Framework 대표적인 모바일 딥러닝 프레임워크 Tensorflow Lite와 Caffe2를 소개하고 각 프레임워크의 장단점, 그리고 매스프레소는 어떠한 프레임워크를 선택하였는 지 소개해드리고자 합니다.
- Etc. (Pruning, Architecture Search) 위에서 진행한 과정 말고 Neural Network Pruning, Weight Clustering, Neural Architecture Search 등 다양한 딥러닝 최적화 테크닉들이 존재합니다. 이와 관련된 다양한 논문들이 있으며 주목할만한 결과를 얻기도 하였습니다. 그러나 내용이 많아 본 글에서는 다루기 어렵기에 간단하게 논문 링크들만 공유하고 다음에 기회가 있으면 자세히 다루도록 하겠습니다.
Progressive Weight Pruning of Deep Neural Networks using ADMM Deep neural networks (DNNs) although achieving human-level performance in many domains, have very large model size that…arxiv.org
Neural Architecture Search with Reinforcement Learning Neural networks are powerful and flexible models that work well for many difficult learning tasks in image, speech and…arxiv.org
3. Base Architecture Selection
2017년에 Google에서 효율적인 연산량을 갖는 딥러닝 모델 Mobilenet을 발표했습니다. 이미 많은 사람들이 효율적인 딥러닝을 위해 사용하고 있는 모델로 그 연산량과 성능은 많이 입증되었습니다. Classification, Segmentation 등 다양한 비전분야에서 사용되고 있으며 이 밖에 더 경량화시킨 Mobilenet v2, Nasnet-mobile, PNasnet-mobile 등 다양한 경량화 딥러닝 모델들이 존재합니다. 본 프로젝트에서는 이러한 경량화 모델들을 적극 사용하여 비교하고자 하였습니다.

이제는 너무나 유명해진 MobileNet Depthwise & Pointwise Convolution (https://arxiv.org/pdf/1704.04861.pdf)
오브젝트 디텍션 방법은 크게 1 Stage Detector와 2 Stage Detector 2가지로 분류됩니다. 두 방법의 핵심적인 차이점은 Region Proposal Network(RPN)를 따로 두느냐 두지 않느냐로 구분됩니다. 1 Stage Detector의 대표적인 방법으로는 Single Shot Detector(SSD), 2 Stage Detector의 대표적인 방법으로는 Faster RCNN이 있습니다. 1 Stage Detector는 RPN을 따로 두지 않고 미리 정의된 Anchor들에 대해서 오브젝트 디텍션을 하는 방법인데 효율적인 연산량을 갖는다는 장점이 있으나 만족할만한 성능이 나오지 않는다는 단점이 있습니다. 2 Stage Detector는 RPN을 따로 두어 Region Proposal을 받고, 해당 Proposal들을 기반으로 다시 오브젝트를 디텍션하는 방법입니다. 더 정확한 오브젝트 디텍션이 가능하다는 장점이 있으나 연산량이 많다는 단점이 있습니다.

FAIR에서 제시한 Feature Pyramid Network (https://arxiv.org/pdf/1612.03144.pdf)
오브젝트 디텍션 성능을 끌어올리기 위해 Facebook AI Research에서 Feature Pyramid Network(FPN)라는 모델을 제시하였습니다. FPN 방법은 U-Net구조를 Feature Extractor Stage에 접목시킨 방법으로 오브젝트 디텍션에서 더 좋은 성능을 올릴 수 있습니다. 그리고 이 FPN 방법을 SSD에 적용시켜 RetinaNet이라는 모델이 제시되었습니다. RetinaNet은 FPN과 SSD을 합쳐 기존 SSD보다 더 좋은 성능을 얻어내었습니다.
Focal Loss for Dense Object Detection The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a…arxiv.org
다양한 모델들을 Tensorflow를 통해 테스트해본 결과 가장 좋은 성능을 냈던 Mobilenet FPN Faster RCNN을 최종 모델 구조로 결정하였습니다. Mobilenet Faster RCNN, Mobilenet FPN SSD는 연산효율은 더 좋았지만 수식 인식 엔진에서 높은 인식률을 요구했기에 Mobile FPN Faster RCNN을 최종 모델로 결정하였습니다. 그 결과 기존 수식 인식 네트워크보다 성능 차이는 크지 않고, 연산량은 100배 더 적은 모델을 구축하였습니다.
4. Float16 & UInt8 Inference
최근에 딥러닝 모델의 상수들을 압축시켜 성능저하 없이 모델 용량, 연산량을 줄이는 방법들이 보고되고 있습니다. 가장 대표적인 방법들로는 16bit의 Half Float으로 트레이닝시키는 방법과 8bit의 Unsigned Integer로 바꿔서 트레이닝하는 방법이 있습니다.
딥러닝 모델의 32 bit float 상수들을 float16으로 변환시켜 학습시키는 방법은 Parameter update 시에 Gradient를 32bit로 하고 inference시에는 16bit 상수들만 사용하여 성능 저하 없이 학습 가능하고 모델 용량을 절반으로 줄일 수 있는 학습법입니다. 모델 용량을 절반 넘게 줄일 수 있다는 장점이 있으나 ARM NEON으로 최적화된 Float16 연산 라이브러리가 없기에 실제 모바일 배포 환경에서는 속도 이득을 얻을 수 없다는 단점이 있습니다.
Mixed Precision Training Deep neural networks have enabled progress in a wide variety of applications. Growing the size of the neural network…arxiv.org
마찬가지 방법으로 32 bit float 상수들을 8bit의 Unsigned Integer로 바꿔서 학습시키는 방법은 모델 상수들을 그룹화하기에 Quantization이라고 불리기도 합니다. 모든 연산을 32bit 연산을 8bit 정수 연산으로 바꿀 수 있기에 굉장히 효율적으로 연산이 가능하다는 장점이 있으나 Mobilenet과 같은 효율적인 구조의 모델에서 Quantization 변환 시 성능이 어느 정도 떨어진다는 단점이 있습니다.
Quantizing deep convolutional networks for efficient inference: A whitepaper We present an overview of techniques for quantizing convolutional neural networks for inference with integer weights…arxiv.org
수식 인식 엔진이 높은 수준의 인식률을 요구하기에, 연산 효율보다 성능 저하가 없는 것이 보장된 Float16 변환을 채택하기로 하였습니다. 비록 실제 모바일 배포 환경에서 속도 이득을 얻을 수 없지만 성능 저하 없이 모델 용량 사이즈를 절반으로 줄일 수 있다는 장점이 있기에 모델 상수들을 Float16으로 변환하기로 결정하였습니다.
5. Mobile Deep Learning Framework
모바일 프레임워크의 가장 중요한 특징은 딥러닝 연산이 해당 플랫폼에 최적화되어 있느냐입니다. 일반적으로 딥러닝 학습에서 많이 사용하는 GPU 제조사인 Nvidia에서는 CUDNN이라는 딥러닝 연산 최적화 라이브러리를 제공하는데 이 라이브러리에서는 딥러닝 연산을 소프트웨어뿐 만 아니라 하드웨어 차원에서도 높은 수준으로 최적화해주고 있습니다. 반면 CPU에서는 소프트웨어/하드웨어적으로 최적화된 라이브러리를 찾기 쉽지 않습니다. 특히 모바일 딥러닝 환경에서 가장 중요한 건 ARM 프로세서 기반으로 연산이 최적화 되어 있느냐인데, 이 부분에 따라서 연산 속도가 2–3배 차이나기도 합니다. ARM 프로세서에 최적화된 라이브러리는 대표적으로 Tensorflow lite, Caffe2가 있습니다.
Tensorflow lite는 가장 유명한 모바일 딥러닝 프레임워크입니다. 많은 튜토리얼들이 존재하고 Graph Transformer는 불필요한 연산들을 손쉽게 최적화하고 Lite model로 변환할 수 있습니다. Mobilenet 구조와 SSD object detector를 TF lite graph로 변환가능한 예제들이 많이 존재해 손쉽게 모바일 최적화를 할 수 있다는 장점이 있습니다. 또한 8bit로 모델을 쉽게 변환할 수 있는 기능을 탑재되어 있다는 장점이 있습니다. 그러나 Faster RCNN 구조를 TF lite graph로 변환 후 실행 중에 에러를 발견하였고 TF lite 디버깅 환경이 잘 구축되어 있지 않아 필요한 기능을 커스터마이징하기 어렵다는 치명적인 단점이 있었습니다.

디버깅을 위해 TF lite 그래프를 시각화한 자료. 디버깅이 불가능할 정도로 어렵다는 치명적인 단점이 있다.
Caffe2는 페이스북에서 발표한 딥러닝 프레임워크로 손쉬운 모바일 환경 배포를 지원합니다. 모델을 Protobuffer 형태로 배포하면 플랫폼에 상관없이 실행 가능하다는 장점이 있습니다. 그러나 튜토리얼 예제가 잘 작성되어 있지 않고 자료가 많지 않아 검색해도 결과가 잘 나오지 않기 때문에 직접 소스코드를 읽어야 한다는 단점이 있습니다. 또한 Python API를 지원하지만 완벽한 Python 환경이 아니기 때문에 디버깅이 쉽지 않다는 단점이 있습니다.

Caffe2는 에러메세지도 심도 있게 읽어야 이해할 수 있다.
Faster RCNN 구조가 Tensorflow lite에서 그래프 변환에 있어서 치명적인 버그가 있었기 때문에 Caffe2 프레임워크를 사용하기로 결정하였습니다. 그러나 Caffe2는 사용자가 많지 않고 문서화가 잘 되어있지 않았기 때문에 개발 중에 많은 이슈가 있었습니다. 최신 Caffe2 프레임워크로 빌드된 모바일 튜토리얼들이 거의 전무하였기에 빌드 과정에서 엄청난 시행착오를 겪었습니다. 그리고 예상과 다르게 행동하거나 지원하지 않는 Operator들이 많았기 때문에 직접 Caffe2의 소스코드를 읽으면서 파이썬 모델들을 수정하고 C++ Custom Operator들을 추가하기도 하였습니다. 특히 학습이 완료된 Float16 텐서를 로드하는 오퍼레이터가 없었기 때문에 이 부분을 직접 구현하였습니다.
6. Conclusion
최종적으로 Caffe2를 이용해 성공적으로 모바일에서 실행 가능한 모델을 만들었습니다. Mobilenet FPN Faster RCNN 모델을 Float 32bit로 트레이닝한 모델의 경우 약 40MB, Float 16bit로 트레이닝한 모델의 경우 모델 용량이 약 20MB로 줄어들었습니다. 초기 수식 인식 엔진 모델이 약 240MB 이었고 많은 아이디어를 도입해 12배 정도 용량을 줄였고 Android / IOS 모두에서 성공적으로 돌아가는 모델을 만들었습니다.

최종 성능 벤치마킹

수식 인식 결과 샘플
Tensorflow lite는 모든 형태의 텐서플로우 그래프 변환을 지원하지 않습니다. 특히 If, While 같은 Flow control ops같은 경우에서 변환이 매끄럽지 않고 CropAndResize 등 구현되지 않은 텐서플로우 오퍼레이터들이 있습니다. 텐서플로우 팀에서는 이 문제를 해결하기 위해 TF Selective ops라는 기능을 현재 개발중인데, 이는 TF lite에 구현되지 않아도 텐서플로우에 있는 오퍼레이터들을 사용할 수 있는 기능입니다. 이 기능을 사용하면 커스텀 오퍼레이터를 구현할 필요 없이 손쉽게 모든 그래프를 바꿀 수 있습니다. 그러나 오퍼레이터들이 ARM 프로세서에 최적화되어 좋은 성능이 나올 수 있을 확실치 않다는 단점이 있습니다.
현재까지 Faster RCNN같은 무거운 오브젝트 디텍터를 모바일로 배포하는 것이 쉽지는 않은 것 같습니다. 실험적인 기능이 많았기에 완벽하게 동작하지 않는 코드들이 많았고 문서나 튜토리얼이 완벽하게 되어있지 않아 직접 코드를 읽고 수정하면서 많은 시행착오를 겪었습니다. 힘든 여정이었지만 내가 최초로 레퍼런스를 뚫어낸다는 도전의식과 매스프레소분들의 응원을 통해 할 수 있었던 것 같습니다. 이 글이 앞으로 저와 비슷한 상황에 직면한 사람들께 좋은 참고자료가 될 수 있었으면 좋겠습니다.
매스프레소에서 함께 성장할 멤버를 찾고 있습니다.
글로벌 교육앱 1위 QANDA(콴다)를 함께 만들어 갈 능력있는 분들을 기다리고 있습니다!!
자세한 사항은 채용 사이트를 통해 확인하실 수 있습니다.
#전직군채용중 #we’re_hiring #글로벌교육앱
 가입하기
가입하기