Character Region Awareness for Text Detection (CRAFT) 논문 리뷰
이 포스트는 논문을 번역한 글이 아니라 논문 전체를 이해하기에는 부족할 수 있으나 Reference에 대한 간략한 설명을 포함하여 논문을 이해하는데에 도움이 될 수 있습니다.
또한 개인의 생각이 포함되어 있어 저자의 의도와는 다른 부분이 있을 수 있으며 잘못된 정보나 개선해야 할 부분에 대한 피드백을 주시면 반영하도록 하겠습니다.
Review Summary
CRAFT는 Character 단위 Detection 정보를 활용하여 이미지에서 텍스트 영역을 찾는 방법을 제안하고 있으며 ICDAR 여러 분야에서 1등을 할 정도로 좋은 성능을 보입니다. 크게 아래 3개의 주제에 대해 다룰 예정입니다.
Text Detection Methods - Word-Level Detection에 한계가 있어 Character-Level Detection을 사용한다.
Methodology - Character를 연결하여 Word를 만드는 과정을 Affinity Box를 예측하고 간단한 알고리즘을 통해 Word를 만드는 문제로 바꾸어 해결한다.
Weakly-Supervised Learning - 데이터가 적은 상황에서도 Pseudo Ground Truth를 통해 학습이 가능한 구조를 사용한다.
Text Detection Methods
다양한 형태의 Text Detection Method가 존재하며 논문에서 소개하고 있는 것은 다음과 같습니다.
Regression-based text detectors
SSD, Faster R-CNN 과 같은 Object Detection Methods를 Text Detection에 맞게 바꾼 연구들이 포함되어 있으며
Rotated Image, Arbitrary shape text에 대응하려는 연구도 많이 진행되었습니다.
그러나, 구조적인 한계가 있어 이 방법으로 가능한 모든 shape의 text에 대해 인식하기에는 어렵다고 합니다. - 모든 shape에 대응할 수 있는 anchor를 만들어 주어야 하고 proposed box의 수를 잘 결정해야 하지만 실행시간과 정확도 사이의 Trade-off가 있다.
Segmentation-based text detectors
Pixel-level에서 Text 영역을 찾는 방식이고 Word-Level Detection과 Character-Level Detection이 가능합니다.
논문에서는 Word-Level Detection에 초점을 맞추어 설명하고 있으며, Character-Level Detection은 뒤에 따로 다루고 있습니다.
End-to-end text detectors
Detection과 Recognition을 동시에 진행하는 구조이기 때문에 detector라 부르는 것이 적합하지는 않을 수 있다고 생각합니다.
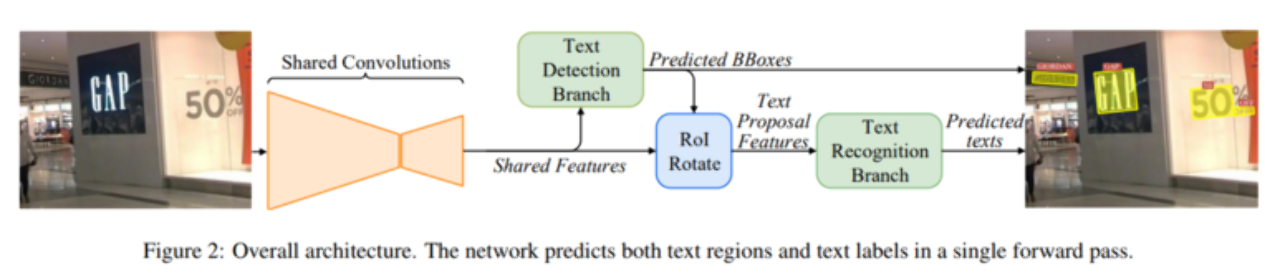
FOTS (https://arxiv.org/pdf/1801.01671.pdf)
Shared Convolution을 사용하여 two-stage 방식에 비해 속도가 빠르다는 장점이 있습니다.
Character-Level text detectors
많은 방법들은 Word Detection을 목표로 하지만 Word를 인식의 기본 단위로 결정하기에는 어려운 부분이 있습니다.
Arbitrary Shape Text에 대응하기 어렵다.
Previous methods trained with rigid word-level bounding boxes exhibit limitations in representing the text region in an arbitrary shape. (Abstract)
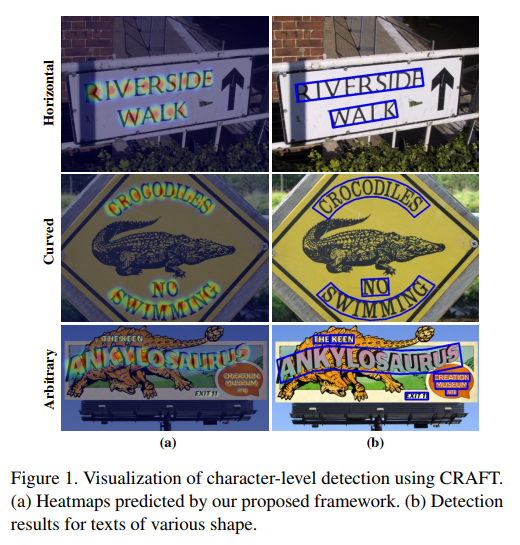
Texts of various shape
2. Word가 무엇인지 정의하는 것이 쉽지 않다.
Most methods detect text with words as its unit, but defining the extents to a word for detection is non-trivial since words can be separated by various criteria, such as meaning, spaces or color. (from paper)
띄어쓰기가 없는 글자도 있습니다.

DEVIEW 2018 (https://tv.naver.com/v/4578167)
3. 다양한 형태의 텍스트를 다루는데 있어 Character 가 기본단위가 되는 것이 자연스럽다.
Imagery texts are usually organized as a hierarchy of several visual elements, i.e. characters, words, text lines and text blocks. Among these elements, character is the most basic one for various languages such as Western, Chinese, Japanese, mathematical expression and etc. It is natural and convenient to construct a common text detection engine based on character detectors. (WordSup)
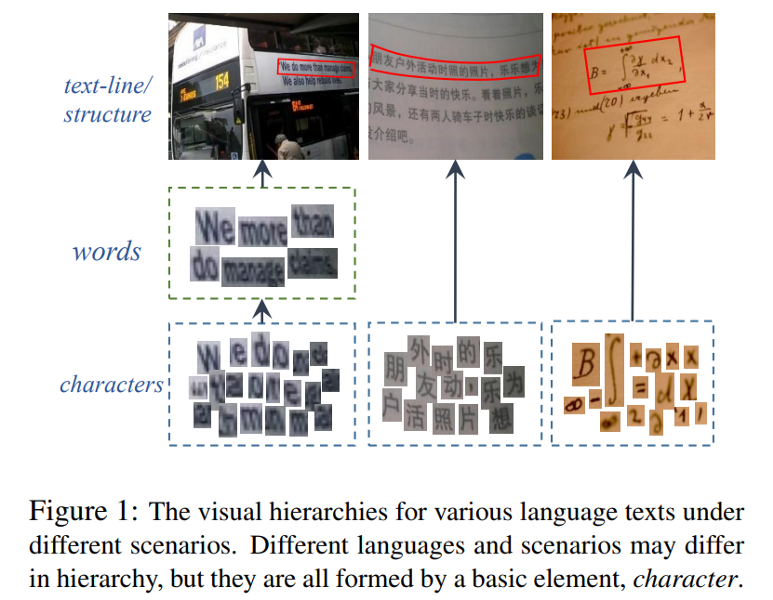
WordSup (https://arxiv.org/pdf/1708.06720.pdf)
Methodology
Architecture
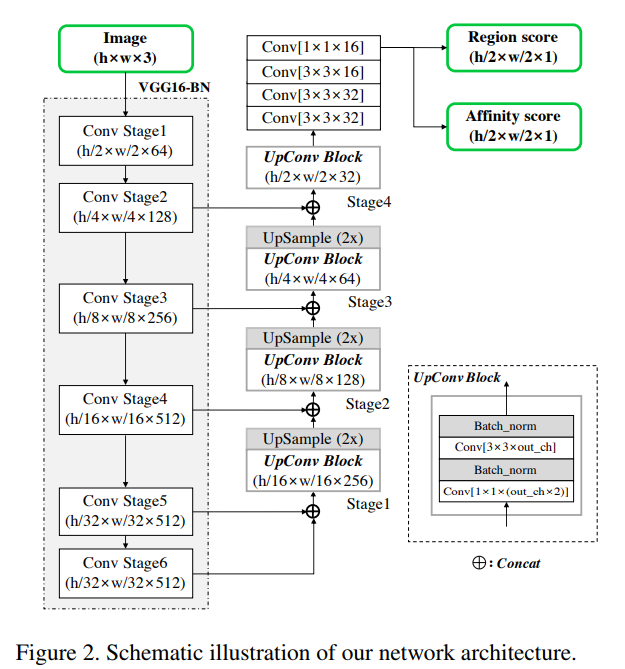
Affinity Score
글자 하나하나의 위치를 찾고 각 글자들 간의 연결을 알고리즘을 통해 만들거나 딥러닝을 통해 예측하려는 시도는 예전부터 있었으나 ([4], [32], [37] from paper) 글자와 글자 사이의 연결에 집중하고 있습니다.
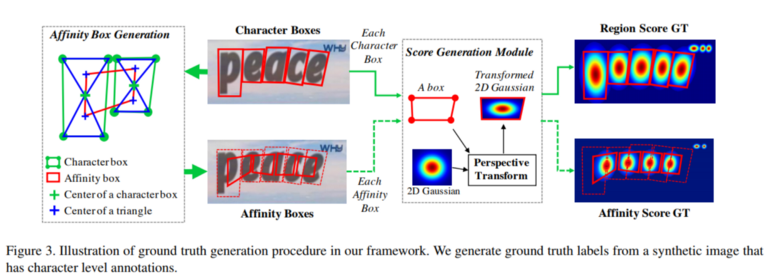
Gaussian Map을 perspective transform 한 결과를 통해 Character Region Score와 Affinity Score의 GT를 만들어 학습에 사용합니다. - Character Region을 예측하는데에 위의 방법을 사용하는 연구는 많이 진행된 것으로 알고 있으나 글자와 글자 사이의 연결을 이러한 방법으로 해결하려는 시도는 알고있는 범위 내에서는 없었으며 개인적으로 이 접근방법이 논문의 하이라이트가 아닐까 생각합니다.
Weakly-Supervised Learning
학습에 필요한 데이터가 없는 상황에서 여러가지 방법을 통해 학습 데이터를 생성하여 학습을 진행할 수 있는 방법을 제안합니다. - WordSup과 유사한 방식이며 참고해도 좋을 것 같습니다
텍스트를 다루는 만큼 Synthetic Image를 생성하는 것이 쉽고 이때에는 완벽한 GT를 얻을 수 있습니다.
Real Image의 경우 학습한 모델에서의 예측 결과와 단어의 길이 정보를 사용하여 데이터를 보다 쉽게 쌓을 수 있습니다.
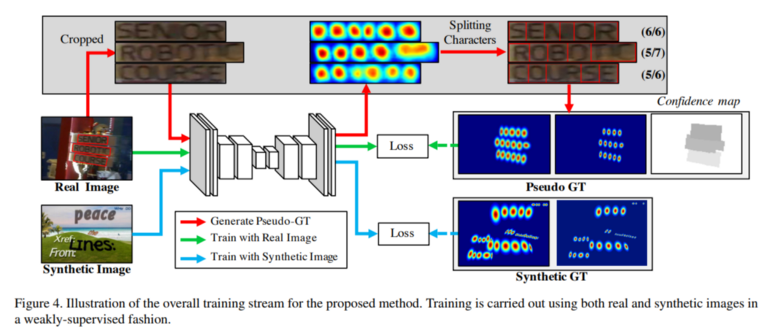
Pseudo GT의 경우 데이터를 신뢰할 수 있는지를 판단하기 위해 텍스트의 길이 정보를 통해 confidence를 계산하며 이 confidence를 활용하여 loss를 update합니다.
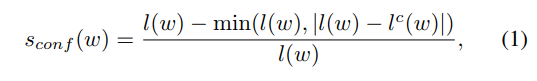
Confidence for each text
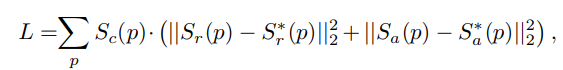
Loss Function
이 구조의 장점은 사람이 GT를 만들지 않더라도 학습이 가능하고, confidence score가 있어 잘못된 pseudo GT로 인한 악영향을 줄일 수 있다는 것입니다.
Results

다양한 형태의 텍스트를 포함한 사진에 대해 좋은 성능을 보임을 알 수 있습니다.
Training 부분을 제외한 코드가 공개되어 있으며 pretrained model을 포함하고 있어 네트워크의 성능을 쉽게 확인할 수 있습니다.
본문에 잘못된 정보가 있다면 [email protected] 으로 연락주세요.
매스프레소에서 함께 성장할 멤버를 찾고 있습니다.
글로벌 교육앱 1위 QANDA(콴다)를 함께 만들어 갈 능력있는 분들을 기다리고 있습니다!!
자세한 사항은 채용 사이트를 통해 확인하실 수 있습니다.
#전직군채용중 #we’re_hiring #글로벌교육앱
 가입하기
가입하기