휴먼스케이프 Software engineer Covy입니다.
본 포스트에서는 이전 포스트 GAN을 활용하여 image to image translation에서 범용적으로 쓰이는 프레임워크를 처음으로 제안한 논문에 대해서 리뷰하려고 합니다. 이 포스트는 이전 포스트 GAN, U-Net에 대한 이해를 바탕으로 진행할 예정으로, 이전 포스트에 대한 내용은 이곳(GAN)과 이곳(U-Net)을 참고하시면 좋습니다. 리뷰하려는 논문의 제목은 다음과 같습니다.
“Image-to-Image Translation with Conditional Adversarial Networks”
논문에 대한 내용을 직접 보시고 싶으신 분은 이곳을 참고하시면 좋습니다.

pix2pix
Objective
논문에서 목적으로 하고 있는 것은 general-purposed image to image translation framework를 구현하는 것입니다. 부연 설명을 하자면, grayscale to color, map to aerial, sketch to photo 등 다양한 분야의 image to image translation에서도 일반적으로 동작할 수 있는 범용적인 framework의 구현을 목적으로 하는 것입니다.
이러한 목표를 위해 선행연구들을 서치한 결과, euclidean distance에 따라서 전체 predicted image와 ground truth 사이의 차이를 image를 최소화시키기 때문에 blurry한 이미지가 나오는 CNN보다는, real과 fake를 구별할 수 없게끔이라는 학습 목표를 가진 GAN이 선명한 이미지를 얻을 수 있다는 점에서 논문에서는 GAN을 선택합니다.
하지만, GAN은 이미지를 생성하는 모델일 뿐이지, input 이미지에 대한 내용을 반영하여 변환된 이미지를 생성할 수는 없었기에, 논문에서는 기존 GAN에 input image에 dependent한 term을 추가한 conditional GAN을 이용합니다.
또한 논문에서는 기존의 image to image translation의 논문들과 다르게 generator로 U-Net 구조, 그리고 discriminator로 patchGAN 구조를 사용하여 효과적인 학습을 진행합니다.
Conditional GAN(cGAN)
기존의 noise vector z로부터 output vector y를 생성해내는 GAN과는 달리 conditional GAN(이하 cGAN)의 경우 noise vector z 뿐만 아니라 input vector x를 이용해 output vector y를 생성합니다.
이 때문에 cGAN의 cost function도 GAN과 크게 다를 것은 없습니다. 다만 특징적으로 다른 것은 discriminator가 real과 fake를 기존에는 generated된 distribution에 대한 정보, 혹은 ground truth(학습에 사용될 데이터) data image distribution에 대한 정보 각각만으로만 구별해 냈다면, cGAN에서는 input image에 대한 distribution 정보도 discriminator가 real과 fake를 구별하는 데 사용하게 됩니다.
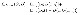
cost function of cGAN
앞서 말씀드린 것과 같이 discriminator의 연산이 기존의 GAN과는 달리 두 개의 파라미터를 필요로 함을 알 수 있습니다. 앞서 GAN 논문 리뷰에서도 설명했지만, discriminator가 real로 구별했을 경우 D값을 1, fake로 구별했을 경우 D값을 0이라 하면, 첫 항은 real로, 둘째 항은 fake로 구별하여 cost function이 최대가 되는 것을 목표로 합니다. 반면 generator는 discriminator가 구별 못하게 하는 fake를 생성하는 것이 목표이기 때문에 discriminator가 둘째 항을 real로 구별하길 원하며, 이에 따라 cost function이 최소가 되는 것을 목표로 합니다.

cost function of GAN for compare the effect using cGAN
논문에서는 unconditional한 경우의 cost function도 정의하여 비교의 용도로 학습을 진행합니다. 위는 그 cost function입니다. 여기에 더해 논문에서는 기존 연구들에서 GAN에 L2 loss를 추가했을 때 더 나은 학습 효과를 보인 것에 착안하여 그것과 비슷하면서도, blurry한 이미지를 덜 생성해 내는 L1 loss term을 추가합니다.

L1 loss term
이를 추가하여 최종적으로 설계한 generator의 objective는 다음과 같습니다.

objective of generator
U-Net
논문에서 사용한 generator의 구조는 U-Net을 따르고 있습니다. 이는 output image의 resolution을 증가시키기 위해서 high resolution을 지닌 input map의 일부를 잘라서 output decoder part에 concatenate 시키는 형태의 방법론으로 구현한 아키텍처입니다. 자세한 사항은 U-Net글에서 확인할 수 있습니다.
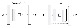
Encoder-decoder VS U-Net
patchGAN
논문에서 사용한 discriminator는 patchGAN의 구조를 사용합니다. patchGAN은 기존의 DCGAN과는 다르게 이미지의 patch 조각을 보고 real/fake 여부를 판단합니다. 이미지의 작은 patch에 대해서 판단하여 각 patch 별로의 real/fake 여부를 판단하는 것이기 때문에 이미지 전체를 연산하는 것보다 연산의 수가 적고 빠릅니다.
이 방식을 통해서 generator는 각각의 이미지 patch 조각들의 진위여부를 속이기 위해서 학습하는 과정이 진행되고, 기존의 전체 이미지를 속이기 위해서 학습하는 방법보다 output image가 더 high resolution을 가질 수 있게 됩니다.
Experiments-Evaluation Metrics
논문에서 그들의 아키텍처/방법론을 평가하기 위해서 사용한 방법은 크게 두 가지로 나누어집니다.
첫 번째로, Amazon Mechanical Turk(이하 AMT)를 실행시켜 생성한 이미지의 real/fake 여부를 판단하는 것입니다. 논문에서는 map generation, aerial photo generation, image colorization 등을 이 방법을 통해서 평가합니다.
두 번째로, pre-trained 된 semantic classifier를 이용해서 생성한 이미지로부터 정확한 object를 구별해 낼 수 있는지를 나타낸 FCN-score를 이용하는 것입니다.
여기서는 논문에서 특징적으로 사용한 구조나 방법론을 평가하기 위한 척도였던 두 번째 방법에 주목하여 진행했던 평가들을 설명하겠습니다.
Evaluation-cGAN Objective Function
논문에서는 앞에서 설명한 cGAN cost function 설계를 평가하기 위해서 FCN-score를 이용합니다.

FCN-scores for various cost functions

Generated output images
GAN이 L1과 cGAN에 비해서 성능이 좋지 않는 이유는 GAN으로 생성하는 이미지는 input image 와 생성되는 output image간의 mismatch로 인해서 발생하는 penalty 항목을 loss에 포함하고 있지 때문입니다.
그 외에 L1만 사용한 것은 blurry한 image를 만들고, 이전의 선행연구에서 밝혀진 바처럼 cGAN과 함께 사용할 때 cGAN만 사용할 때보다 visual artifcat가 적게 나타남을 볼 수 있습니다.
Evaluation-Generator(U-Net)
논문에서는 앞에서 설명한 U-Net 구조를 평가하기 위해서 FCN-score를 이용합니다.

FCN-scores for generator strucuture

Generated output images
표에서 보이는 바와 같이 U-Net의 경우가 기존의 encoder-decoder 구조보다 더 높은 FCN-score를 보임을 알 수 있습니다. 이는 앞서 설명한 것 처럼 skip-connection을 통해 encoder 부분의 high resolution을 decoder 부분에 전해주었기 때문입니다.
그림에서 보이는 것처럼 U-Net을 사용할 경우가, L1+cGAN의 복합적인 cost function을 사용할 경우가 더 고해상도의 선명한 이미지를 생성해냄을 보여주었습니다.
Evaluation-Discriminator(patchGAN)
논문에서는 앞에서 설명한 pathGAN 방법론을 평가하기 위해서 FCN-score를 이용합니다.

FCN-scores for discriminator patch size

Generated output images
표에서 보이는 바와 같이 70x70의 patch size로 나누어 진위여부를 판단한 경우가 기존의 1x1의 pixelGAN이나 286x286의 imageGAN 구조보다 더 높은 FCN-score를 보임을 알 수 있습니다. 이는 앞서 설명한 것 처럼 적절한 size의 patch로 이미지를 나누어 discriminate 과정을 진행할 경우 localization과 context extraction에 있어서 극값들보다 유리하기 때문입니다.
그림에서 보이는 것처럼 70x70의 patch size을 사용할 경우가, L1이나 이미지 전체 크기의 patch 를 사용한 경우보다 전체적으로도, 세부적으로도 선명한 이미지를 만들어냄을 볼 수 있었습니다.
Conclusion
이것으로 논문 “Image-to-Image Translation with Conditional Adversarial Networks”의 내용을 간단하게 요약해보았습니다. 이미지 변환에서 자주 봐오던 논문인데 이 기회에 읽게 되어 좋았던 것 같습니다.
여기서 다루지는 않았지만 AMT를 사용해 진행한 평가도 있습니다. 다만 여기서 도출된 결과는 논문의 아키텍처/방법론이 비교대상들 중에 가장 좋은 결과가 아니었으며, 논문의 큰 흐름과는 다른 결을 설명하기 때문에 제외했습니다. 관심 있으신 분은 한 번쯤 읽어보셔도 좋을 것 같습니다.
Get to know us better! Join our official channels below.
Telegram(EN) : t.me/Humanscape KakaoTalk(KR) : open.kakao.com/o/gqbUQEM Website : humanscape.io Medium : medium.com/humanscape-ico Facebook : www.facebook.com/humanscape Twitter : twitter.com/Humanscape_io Reddit : https://www.reddit.com/r/Humanscape_official Bitcointalk announcement : https://bit.ly/2rVsP4T Email : support@humanscape.io
 가입하기
가입하기



