소개
시작은 캐글(kaggle)이었다. 캐글이 무엇인지 처음 읽는 분들을 위해서 잠깐 설명하자면, <캐글>은 과학자들이 통계적 문제를 놓고 경쟁하는 온라인 플랫폼이다. 비유하자면 엔지니어들의 <쇼미더머니>랄까. 다만 누가 더 랩을 잘 하는가에 대한 평가는 심사위원이 아니라 수치로 집계된다. 지원자들은 학력, 나이에 관계없이 공개된 데이터를 다운로드하고, 평등한 시간에 문제를 푼다. 점수가 나온다. 점수는 리더보드에 실시간으로 집계된다. 마지막으로 마감 시간까지 최고의 솔루션을 제공한 팀이 상금을 탄다. 요약하자면 문제를 풀고, 그것을 제일 잘 푸는 팀이 돈을 번다. 우승 상금에 세금을 떼는가는 순위권에 들었던 적이 없어 잘 모르겠다. 아무튼 캐글의 재미난 점이 있다면, 세상에 숨어있는, 속된 말로 ‘재야의 고수들’이 참 많구나 하는 인식과, 고수들은 유명 기업에만 있는 것이 아니라는 점이다. 고수들은 금융계 분석가, 공학자, 대학원생, 웹 개발자, 헬스 케어 종사자 등 다양한 직업군으로 이 세상 어딘가에 함께 살고 있었다.<!--쇼미더머니--><!--캐글-->
캐글은 전 세계가 검색하고 건드려 보는(?) 데이터 경진 플랫폼이다. <쇼미더머니>에 우승자 인터뷰가 있듯, 캐글도 우승자 인터뷰[1]가 있다. 이곳에는 단순히 데이터와 검증 방법을 설명하는 것 외에도 인터뷰이들의 직업, 사생활, 아이디어가 나온 장소(?), 에피소드 등, 인간적인 부분도 확인할 수 있는데, 이들은 공통적으로 아이디어를 공유하는데 제법 열려있다(당연히 아닌 인터뷰도 있다). 다만 오픈 콘테스트 우승자는 본인이 사용한 툴을 모두 공개해야 한다. 그리고 필자는 이 곳에서 xgboost(Extreme Gradient Boosting)를 처음 알았다.<!--쇼미더머니-->
심심찮은 비중의 우승자들이
**의 장점**
- 훌륭한 그라디언트 부스팅 라이브러리. 병렬 처리를 사용하기에 학습과 분류가 빠르다
- 유연성이 좋다. 평가 함수를 포함하여 다양한 커스텀 최적화 옵션을 제공한다
- 욕심쟁이(Greedy-algorithm)를 사용한 자동 가지치기가 가능하다. 따라서 과적합(Overfitting)이 잘 일어나지 않는다
- 다른 알고리즘과 연계 활용성이 좋다. xgboost 분류기 결론부 아래에 다른 알고리즘을 붙여서 앙상블 학습이 가능하다 ResNet 마지막 바로 이전 단을 Feature layer로 응용하는 것과 비슷하다.
요약하자면 빠르고 유연하다는 게 xgboost가 가진 장점이다. 다큐먼트[2]를 찾아 읽었다. 적용도 그리 어렵지 않아 보였다. 그렇지만 xgboost가 그저 시도하기 쉽기 때문에 실험을 시작해선 안 될 것이다. 이 기술이 우리 팀에 실제로 필요한가 판단이 필요했다. 간단한 고민에 근거를 적기 시작했다.
왜 딥러닝 학습 기법 소개가 아니냐고?
요즘 딥러닝, 참 핫(hot)하고, 잇(it)하고, 댓(that)하다. 어떤 딥러닝 기계 학습은 필자보다 학부 재학생이 훨씬 더 깊게 알고 있는 경우도 있다. 그렇지만 딥러닝 학습 기법이 모든 데이터 문제의 만능 솔루션이라고 말할 수는 없다. 여기에는 다양한 이유를 댈 수 있겠지만 <차원의 저주The="" Curse="" of="" Dimensionality="">가 있다. 차원의 저주란, 데이터의 차원이 증가할수록, 해당 공간의 크기가 기하급수적으로 증가하기 때문에 데이터 밀도가 희박해져 문제를 해결하기 어려워지는 것을 말한다. 큰 면적을 칠하는데 손톱만 한 붓은 비효율적이다. 반대로 세밀한 표현을 해야 하는 곳에 롤러는 적합하지 않은 도구다. 마찬가지로 딥러닝 학습 기법은 데이터의 숫자만큼이나 피쳐가 풍부한 문제에 적합하다. 보유하고 있는 데이터의 숫자가 많지 않을 때도 문제다. 딥러닝 학습 기법이 아주 훌륭한 미래 먹거리라는 말엔 동의하지만, 모든 데이터 문제를 딥러닝 학습으로 뚝딱 해결할 수 있는 것은 아니다.<!--차원의-->
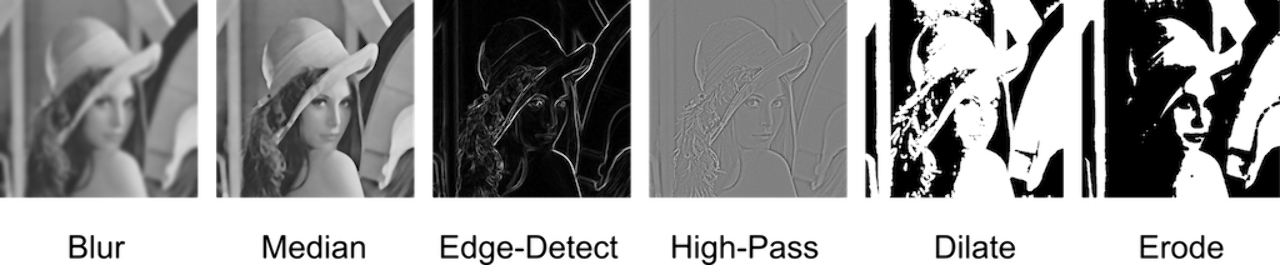
초기 데이터 분석가들은 필터(filter)를 사용해서 이미지 차원을 효과적으로 축소할 수 있지 않을까 생각했다. 그리고 필터를 적용한 결과를 얕은(shallow) 기계 학습에 사용했다. 결과는 좋지 않았다. 그들은 시금치를 물에 너무 오래 데쳤다. 그러니까, 이미지 정보를 요약하면서 얻게 되는 유용한 정보의 양 보다 과정 속에 손실되는 정보가 훨씬 많았다.

그렇지만 과학자들은 실패 대신 뽀샵(?)을 얻었다. 피부 뽀얗게 하기, 턱 깎기, 다리 늘리기, 외곽선 따기 등. 우리가 지금 쓰고 있는 수많은 포토샵 필터들은 과학자들이 이미지 정보의 차원을 효율적으로 축소하다 발견하게 된 부수 효과(additional effect)다. 세상에서 가장 미감이 떨어진다고 평가받는 직업군 종사자들이 쏘아 올린 작은 공이랄까. 물론 의도한 것은 아니었다. 시작은 다차원 정보를 가공해서 액기스를 뽑아내기 위한 방법 모색이었니까. 어쨌든, 다차원 데이터에 필터를 씌워 기존의 얕은 기계학습에 끼워 맞추는 것은 좋지 않은 해법임이 드러났다. 결국 과학자들은 딥러닝 학습 기법이 다차원 처리 문제에 적합한 솔루션임을 알아낸다. 다만 다차원 처리 모델을 구축하기 위해선 어마어마한 숫자의 병렬 처리 머신이 필요하다. 그래픽카드 얘기다. 컴퓨터 업그레이드에 관심이 있는 분들이라면 알고 있겠지만, 요즘 그래픽카드 재고가 바닥이다. 그 많던 그래픽카드들은 누가 다 먹지 않았다. 요즘 그래픽카드는 채굴과 기계 학습을 위해 팬을 돌리느라 바쁘다.