이번 포스트에서는 강화학습에서 reward shaping의 기반이 되는 논문인 “Policy invariance under reward transformation: Theory and application to reward shaping” (A. Y. Ng et al., 1999) [1]을 읽고 정리한 내용을 공유합니다.
글쓴이의 의견이나 부연 설명은 이 문장과 같이 블록으로 표시합니다.
Introduction
강화학습에서 task는 Reward function을 통해 표현됩니다. 이 reward function에 변화를 주는 것으로 학습의 성능을 향상시킬 수 있습니다. 이를 Reward shaping 이라고 합니다. 하지만 reward function은 굉장히 민감하기 때문에 reward shaping의 방법에 따라 agent는 의도와 다른 행동을 하기도 합니다. 본 논문에서는 이런 의도하지 않은 학습 결과를 bug라고 표현하며 그 예시로 두 가지 경우를 설명합니다.
- 자전거 주행 agent를 빨리 학습시키기 위해 goal 방향으로 갈때 positive reward를 주었더니 시작 지점을 중심으로 원을 그리며 도는 agent가 되었다. 이유는 goal에서 멀어질때 penalty를 안주었기 때문에 계속 돌기만 해도 goal에 가까워질때 받은 positive reward가 무한히 쌓이기 때문이다.
- 축구 로봇을 학습할 때 공을 계속 점유하고 있는 것이 중요하다. 그래서 공을 건드릴 때 reward를 주었더니 공 바로 옆에서 진동하는 agent가 되었다. 공을 계속 건드려서 reward를 반복적으로 받을 수 있기 때문이다.
위의 예시에서 우리가 바라는 것은 자전거 주행 agent는 goal에 도착하는 것이고 축구 로봇은 공을 상대 골대에 넣는 것입니다. 하지만 잘못된 reward shaping으로 전혀 다른 목표를 달성하는 agent를 학습시키게 되었습니다. 이처럼 reward shaping은 강화학습의 성능 향상을 위해 효과적인 방법이지만 의도한 방향으로 shaping 하는 것은 어렵습니다. 특히 위와 같이 positive reward가 계속해서 쌓이는 것을 positive reward cycle 이라고 논문에서 표현합니다.
이런 현상이 발생하는 이유는 reward function에 따라 agent가 학습하고자 하는 optimal policy가 아닌 suboptimal로 잘못 학습했기 때문입니다. 본 논문에서 optimal policy는 우리가 해당 문제에 대해 agent에게 학습시키고자 하는 정책이고 suboptimal은 우리가 원하는 policy는 아니지만 높은 reward를 받을 수 있는 정책을 말합니다. reward function의 변화가 학습하고자 하는 policy에도 영향을 주어 reward를 최대로 받는 방향으로 학습하여도 우리가 원하지 않는 방향으로 행동하는 agent로 학습되는 것입니다. 그렇기 때문에 우리는 reward function에 변화를 주어도 optimal policy가 변하지 않는 reward function의 형태가 필요합니다. 이런 성질을 본 논문에서 Policy invariance이라고 표현합니다.
본 논문에서는 reward function이 변화에 대해 policy invariance를 보장하는, 특히 positive reward cycle을 방지하는 reward function의 형태를 제안합니다.
Preliminaries
Definitions
(finite-state) Markov decision process (MDP) $M$ : $(S, A, T, \gamma, R) $
- $S$ : a finite set of states
- $A$ : a set of actions
- $T$ : the next state transition probabilities
- $\gamma$ : discount factor
- $R$ : reward function, $R: S \times A \times S \mapsto \mathbb{R}$ with $R(s, a, s’)$
$\pi$ : policy over set of states $S$ is any function $\pi : S \mapsto A$
Value function : $ V^{\pi}_{M}(s) = E[r_1 + \gamma r_2 + …; \pi, s만] $
Q-function : $ Q^{\pi}_{M}(s, a) = E_{s’ \sim P_{sa}(\cdot)}[R(s, a, s’) + \gamma V^{\pi}_{M}(s’) ] $
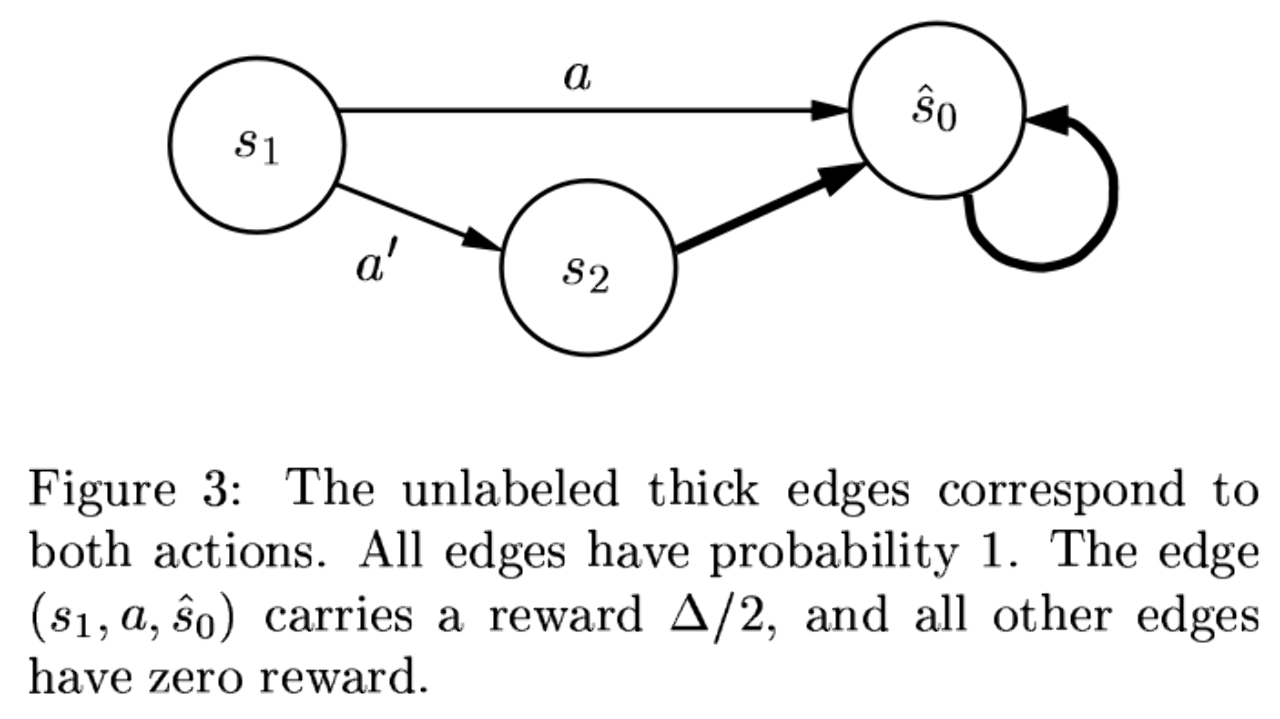
$\textbf s_0$: 본 논문에서는 $s_0$를 absorbing state라 하며, undiscounted MDP($\gamma$ = 1) 일 때 더이상 reward를 주지 않는 state를 표현합니다. 이는 episodic task를 continuing task로 일반화할 때 terminal state와 같은 역할을 합니다. $s_0$에서는 모든 action이 $s_0$로의 state transition (상태 전이) 만을 발생시킵니다. 아래 그림이 하나의 예시입니다. (본 논문의 figure 3)[2]
일반적으로 $s_0$는 episode의 가장 첫번째 state를 표현하지만 본 논문에서는 absorbing state를 뜻합니다.
Shaping Rewards
본 논문에서는 reward shaping function을 추가한 새로운 reward function 형태를 제안합니다.
Error converting from LaTeX to MathML
<math xmlns="http://www.w3.org/1998/Math/MathML">
그리고 $R’$ 을 이용해 MDP를 새롭게 정의합니다.
Error converting from LaTeX to MathML
$F$ 는 shaping reward function 라고 합니다. $F$를 이용해 원하는 shaping term을 추가할 수 있습니다. 예를들어 agent가 goal에 가까워지도록 reward shaping을 하고 싶다면 다음과 같이 $F$를 정의할 수 있습니다.
Error converting from LaTeX to MathML
$M’$은 $M$과 같은 state, action, transition probablities, discount factor를 사용하기 때문에 강화학습 알고리즘을 동일하게 적용할 수 있습니다.
우리의 목표는 정의한 MDP 모델과 강화학습 알고리즘을 이용해 최적의 policy를 찾아내는 것입니다. 그러기 위해서는 다음의 질문들에 대답할 필요가 있습니다.
- 어떤 형태의 $F$ 를 사용해야 $M’$ 에서의 optimal policy가 $M$에서도 동일하게 optimal policy라는 것을 보장할 수 있을지?
- 이 때의 $M’$는 positive reward cycle을 방지할 수 있는지?
Main results
이번 절에서는 어떤 형태의 $F$가 policy invariance를 보장하는지 알아봅시다.
앞서 Introduction에서 자전거 문제를 예시로 들었습니다. 이 문제에서 단순히 goal로 가까워질때 추가적인 reward를 발생시켰고, 이로 인해 시작지점을 기준으로 원을 그리며 계속해서 회전하는 policy가 학습되었습니다. 이런 현상이 발생하는 이유는 agent가 특정 state를 순환($ s_1 \rightarrow s_2 \rightarrow … \rightarrow s_n \rightarrow s_1 \rightarrow … $)하는 경우에 $F$의 총합이 0보다 큰 값을 갖게 되기 때문입니다.
Error converting from LaTeX to MathML
Goal에 도달하는 agent를 학습시키기 위해서는 목적을 성취(goal에 도달)하는 경우에 대해서만 positive reward를 발생시켜야 합니다. 허나, 위의 경우 $F$에 의해 특정 state들을 순환하는 것으로도 reward가 증가하게 되고, 그로 인해 agent는 특정 구간을 순환하는 suboptimal policy를 학습하게 됩니다. 이러한 positive reward cycle 문제를 해결하기 위해 본 논문에서는 다음과 같은 형태의 $F$를 제안합니다.
Error converting from LaTeX to MathML
여기서 $\Phi$ 를 potential function 이라 하며 $F$ 를 potential-based shaping function 이라고 합니다. $F$ 가 다음 state와 현재 state에 대한 함수의 차이로 정의되었기 때문에 위의 예시처럼 cycle이 발생하더라도 reward가 계속해서 증가하지 않습니다.
Error converting from LaTeX to MathML
더 나아가 본 논문에서는 transition probablity와 reward function이 prior knowledge로 주어지지 않았을 때, potential-based shaping function $F$가 policy invariance를 보장하는 유일한 $F$임을 증명합니다.
Theorem 1

임의의 $S$, $A$, $\gamma$에 대해 임의의 shaping reward function는 다음과 같습니다.
<math xmlns="http://www.w3.org/1998/Math/MathML">
이때, 모든 $s \in S - {s_0}, a \in A, s’ \in S$에 대해 아래 식을 만족하는 real-valued function $\Phi: S \mapsto \mathbb{R}$ 가 존재하면 $F$를 potential-based shaping function 이라고 합니다.
Error converting from LaTeX to MathML
그리고 potential-based shaping function $ F $ 는 optimal policy consistency를 보장하기 위한 필요충분 조건입니다.
- (충분조건) $F$ 가 potential-based shaping function 이면 $M’$에서의 모든 optimal policy는 $M$에서도 optimal이다.
- (필요조건) $F$ 가 potential-based shaping function이 아니라면 $M’$에서의 optimal policy가 $M$에서도 optimal임을 만족하는 transition과 reward function이 존재하지 않는다.
Theorem 1에 따르면 위에서 언급한 optimal policy consistency를 만족하는 shaping function $F$가 식 (2)의 형태이고, 이 형태가 optimal policy consistency를 만족하는 유일한 $F$입니다.
Proof: 충분조건
MDP $M$에 대한 optimal Q-function $Q^{*}_{M}(s,a)$는 다음과 같습니다.
Error converting from LaTeX to MathML
이 식에 $\Phi$을 추가해서 전개합니다.
$$ \begin{align} Q^{*}_{M}(s,a) - \Phi(s) &= E_{s’ \sim P_{sa}(\cdot)} \bigg[R(s,a,s’) + \gamma \big(\underset{a’ \in A}{\max} Q^{*}_{M} (s’, a’) + \Phi(s’) - \Phi(s’)\big)\bigg] - \Phi(s) \\
&= E_{s’ \sim P_{sa}(\cdot)} \bigg[R(s,a,s’) + \gamma \Phi(s’) - \Phi(s) + \gamma \big(\underset{a’ \in A}{\max} Q^{*}_{M} (s’, a’) - \Phi(s’)\big)\bigg] \\
\end{align} $$
여기서 $ \hat Q_{M’} (s,a) \triangleq Q^{*}_{M}(s,a) - \Phi(s) $ 라 정의하고 $F(s,a,s’) = \gamma \Phi(s’) - \Phi(s)$ 로 치환합니다.
$$ \begin{align} \hat Q_{M’} &= E_{s’ \sim P_{sa}(\cdot)} \bigg[R(s,a,s’) + F(s,a,s’) + \gamma \underset{a’ \in A}{\max} \hat Q_{M’} (s’, a’)\bigg] \\
&= E_{s’ \sim P_{sa}(\cdot)} \bigg[R’(s,a,s’) + \gamma \underset{a’ \in A}{\max} \hat Q_{M’} (s’, a’)\bigg] \\
\end{align} $$
위 식에 따르면 $ \hat Q_{M’} (s,a) $는 결국 MDP $ M’(S, A, T, R’, \gamma) $ 에서의 Q function $ Q_{M’} (s,a)$ 와 같은 형태가 됩니다. 그리고 $M’$이 undiscounted case ($ \gamma = 1 $)이고 $\Phi(s_0) = 0 $이라 가정했을 때 Error converting from LaTeX to MathML 을 만족하게 됩니다. 따라서 $\hat{Q}_{M’} (s,a)$는 Bellman equation을 만족하며 unique optimal Q-function을 반드시 갖게 됩니다.
그러므로 $M’$에서의 optimal policy $\pi^*_{M’}(s)$는 다음 식을 만족합니다.
$$ \begin{align} \pi^*_{M’}(s) &\in \underset{a\in A}{\arg\max} Q^*_{M’}(s,a) \\
&= \underset{a\in A}{\arg\max} Q^*_{M}(s,a) - \Phi(s) \\
&= \underset{a\in A}{\arg\max} Q^*_{M}(s,a) \end{align} $$
즉, $M’$에서의 optimal policy $\pi^*_{M’}(s)$는 $M$에서 또한 optimal policy임을 알 수 있습니다.
필요조건의 증명은 논문의 Appendix A를 참고하시기 바랍니다.
위의 Theorem 1의 필요충분 조건에 대한 증명을 통해 potential-based shaping function이 policy invariance를 보장하는 유일한 $F$임을 증명하였습니다. 그렇다면 potential-based shaping function의 $\Phi$는 어떤 식으로 정의해야할까요? 논문에서는 Corollary 2를 통해 $\Phi$를 구하는 한가지 방법을 서술합니다.
Corollary(따름 정리)는 Theorem으로부터 바로 증명할 수 있는 참인 명제를 말합니다.
Corollary 2
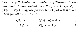
$ F(s,a,s’) = \gamma \Phi(s’) - \Phi(s) $ 이고 $ \gamma = 1 $ 일 때 $ \Phi(s_0) = 0 $를 가정하면, 모든 $ s \in S, a \in A $ 대해 다음 식을 만족합니다.
$$ Q^*_{M’}(s,a) = Q^*_{M}(s,a) - \Phi(s), \\
V^*_{M’}(s) = V^*_{M}(s) - \Phi(s). $$
Proof: Corollary 2
식 (3)은 Theorem 1의 충분조건의 증명과정을 통해 증명되었습니다. $ V^*(s) = \underset{a \in A}{\max}Q^*(s,a) $ 이기 때문에 식 (3)을 만족하면 식 (4)도 만족합니다.
Corollary 2를 통해 $ V^*_{M’}(s) = V^*_{M}(s) - \Phi(s) $이 참임을 알게 되었습니다. 논문에서는 (4)를 통해 $ \Phi $의 가장 쉬운 형태를 제안합니다.
potential-based function
실제 환경에서 $ \Phi $를 정의하기 위해서는 domain에 대한 expert knowledge가 필요합니다. 만약 domain knowledge (MDP $M$)를 충분히 알고 있다면 $\Phi$를 다음과 같이 가정할 수 있습니다.
<math xmlns="http://www.w3.org/1998/Math/MathML">
$\Phi$를 위와 같이 가정하면 Corollary 2의 (4)에 따라 $M’$에 대한 value function은 $V^*_{M’}(s) \equiv 0$입니다. 논문에서는 이런 형태의 value function이 학습에 용이하다고 합니다. 또한 위와 다른 형태의 $\Phi$를 이용해도 충분히 policy invariance를 보장한다고 주장합니다.
$M’$에서의 (near-) optimal policy가 $M$에서도 (near-) optimal policy임을 보장한다 라고 서술하며 Remark 1 을 통해 optimal이 아닌 near optimal 에서도 Theorem 1이 성립함을 언급합니다.
Experiments
Experiments 절에서는 두 가지 grid world 환경에서 potential-based shaping function에 변화를 주며 비교 실험한 결과를 보여줍니다. 본 논문에서는 이 실험을 통해 학습 속도 향상을 위한 합리적인 $\Phi$를 정하는 방향을 설명하는 것이 목적이라고 말합니다.
10 x 10 grid world
10 x 10 grid world 환경은 no discount setting ($ \gamma = 1 $)이며 매 step 당 -1의 reward(penalty)를 받습니다. 1 step action을 할 때 80% 확률로 exploitation 하고 20% 확률로 exploration (random action) 합니다. 저자들은 이전 절에서 좋은 shaping potential $ \Phi(s) = V^*_{M}(s) $ 를 제안했습니다. 이 실험환경에서의 $ V^*_{M} $ 은 현재 state에서 Goal 까지의 Manhattan distance로 볼 수 있습니다. 여기에 80%의 확률로 exploitation하는 것을 감안하여 $V^*_{M}$에 가까운 $\Phi$ 를 다음과 같이 정의합니다.
<math xmlns="http://www.w3.org/1998/Math/MathML">
그리고 $V^*_{M}$와 좀 더 먼 $\Phi$ 에 대해서도 shaping potential이 잘 동작하는 것을 보이기 위해 $ \Phi(s) = 0.5 \Phi_0(s) = 0.5 \hat{V}_M(s) $ 에 대해서도 실험합니다. 실험 결과는 아래와 같습니다.

위 그래프를 통해 $0.5 \Phi_0(s)$와 $\Phi_0(s)$를 shaping potential로 사용했을때, shaping을 사용하지 않은 경우에 비해 학습이 빠른 속도로 수렴함을 확인 할 수 있습니다. 또한 $0.5\Phi_0(s)$를 사용하더라도 $\Phi_0(s)$를 사용했을 때와 거의 유사하게 학습 속도가 향상됨을 보여줍니다. 나아가 조금 더 큰 환경인 50 x 50 grid world 환경에서도 potential-based shaping reward를 사용한 경우에 성능이 더 빠르게 향상됨을 확인 할 수 있습니다.
5 x 5 grid world with subgoals
이번 실험에서는 subgoal이 있는 환경에서도 potential-based shaping reward이 잘 작동하는지 확인합니다.
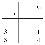
Action과 reward function의 설정은 이전 10 x 10 grid world 환경과 동일합니다. 위 그림의 grid 내부에 표시된 숫자는 각각 flag를 의미하고, agent는 모든 flag를 순서대로 (오름차순) 획득한 뒤 goal에 도착해야합니다. 이 환경에 대한 potential-function을 정의해봅시다. 만약 subgoal의 위치를 모두 알고 있고 이전 환경과 동일하게 80%의 exploitation을 한다면 우리는 goal에 도착하기까지의 timestep t를 예측할 수 있습니다. 이 환경에서는 이전 subgoal에서 다음 subgoal로 가기까지 필요한 step의 갯수가 모두 유사하기 때문에 n번째 subgoal에 도달하기 위한 step은 $((5-n_s)/5)t$ step이라고 할 수 있습니다. 이때 $n_s$는 $s$ 일때 통과한 subgoal의 수가 됩니다.
위에서 도출한 식을 이용하여 potential-function을 다음과 같이 정의합니다. <math xmlns="http://www.w3.org/1998/Math/MathML">
0.5는 일반적으로 agent가 n번째 subgoal과 n+1번째 subgoal 중간에 있기 때문에 이를 보정해주기 위한 값입니다.
또 다른 potential-function으로 10 x 10 grid world 환경에서 사용했던 $\hat{V}_M(s)$를 사용합니다. <math xmlns="http://www.w3.org/1998/Math/MathML">

위 그래프는 위에서 부터 no shaping, $\Phi = \Phi_0(s)$, $\Phi = \Phi_1(s)$에 해당합니다. 이전 실험에서 정의한 $\Phi_1$ 뿐만 아니라 새로 정의한 $\Phi_0$을 사용하였을때에도 마찬가지로 shaping을 사용하지 않은 경우보다 학습속도가 향상되었음을 확인 할 수 있습니다.
Discussion and Conclusions
이번 논문에서는 reward shaping을 위한 function $F$를 제안하였습니다. $F$는 potential-based shaping reward $\gamma \Phi(s’) - \Phi$로 정의하며 이것이 (near-) optimal을 유지하는 shaping reward임을 증명하였습니다. 또한 실험을 통해 distance-based 환경과 subgoal-based 환경에서 potential function을 정의해보고 성능이 향상됨을 확인하였습니다. 이번 논문에서 알아본 potential-based shaping function의 형태는 추후 IRL과 이후의 reward shaping 논문에서 계속해서 사용되고 인용됩니다.
Reference
[1] A. Y. Ng et al., “Policy invariance under reward transformation: Therory and application to reward shaping.” Proceedings of the Sixteenth International Conference on Machine Learning(pp.278-287), 1999.
[2] Sutton, R. and Barto, A., “3.4 Unified Notation for Episodic and Continuing,” in Reinforcement Learning: An Introduction, 2nd ed., MIT Press, 2018.