지난번 글에서 설명했듯이 이더리움은 Modified Merkle Patricia Trie를 4가지 용도로 사용한다. 이 중 State Trie와 Storage Trie는 변경되는 데이터를 효율적으로 저장하고 검증하기 위해서 사용된다. 하지만 Transaction Trie와 Receipts Trie는 변경되는 데이터가 대상이 아니다. 이 두 trie는 하나의 블록에서 사용된 트랜잭션과 그에 의해 생성된 receipt의 검증을 위해서만 사용되는 휘발성 데이터다.
이더리움이 두 가지 목적을 위해 같은 데이터 구조를 사용하는 이유는 같은 구현을 공유하기 위해서였다. 하지만 목적이 다르기 때문에 Transaction Trie나 Receipts Trie를 생성하는데 최적화된 코드는 State Trie나 Storage Trie를 생성하는데 필요한 코드와 다르다. 실제로 Parity는 각각의 용도로 다른 코드를 사용한다. 그렇다면 Transaction Trie나 Receipts Trie를 위해 애초에 같은 Trie를 사용할 이유가 없지 않았을까?
현재 코드박스에서 개발하고 있는 코드체인의 transactions_root와 invoices_root는 이런 고민이 반영됐다. 그래서 UTXO를 저장하는 Merkle Patricia Trie와는 다른 구현을 사용하기로 결정했다. 그렇다면 transactions_root와 invoices_root에 필요한 특성은 무엇이 있을까?
최소한의 필요조건은 데이터를 검증할 수 있어야 한다는 것이다. 이 검증은 단순히 데이터셋을 검증할 뿐 아니라 데이터의 순서도 일치하는지 확인해야 한다. 여기까지가 이더리움을 비롯한 일반적인 블록체인에서 필요한 특성이다. 코드체인에서는 여기에 몇 가지 요구사항이 더 들어갔다.
우선 구현이 간단해야 한다. 간단해야 한다는 것은 코드가 단순하다는 것뿐 아니라 메모리 사용량이 적고, 실행하는데 시간이 적게 걸려야 한다는 것을 의미한다. 이는 코드체인이 라이트 클라이언트를 고려하고 있기 때문이다.
다음으로 전체 트랜잭션을 검증할 수 있어야 한다는 것이다. 이는 다른 블록체인에 없는 코드체인에만 존재하는 특성이다. 코드체인이 동기화를 맞추는 방법에는 Snapshot Sync가 있다. Snapshot Sync는 이력을 다 받을 필요 없이 신뢰할 수 있는 헤더 하나만 있으면 해당 블록을 받은 것과 같은 상태로 동기화되도록 하는 방법이다. 이를 위해서 하나의 헤더만으로 전체 트랜잭션을 검증할 수 있어야 한다.
마지막으로 incremental 하게 만들 수 있어야 한다. 코드체인의 transactions_root는 전체 트랜잭션 목록을 검증할 수 있어야 하기 때문에 incremental 하게 만들 수 없다면 블록이 쌓여갈수록 검증에 필요한 시간이 길어지게 된다. 이를 방지하기 위해 incremental 하게 만들 수 있어야 한다는 것이 필수적이다.
이런 조건들을 만족시키기 위해서 이더리움이 사용하는 Merkle Patricia Trie는 가장 먼저 배제됐다. 이는 전체 데이터에 대해서 incremental하게 만들 수 있지만 Trie를 구성하는데 드는 오버헤드가 컸다.
그다음으로는 전통적인 Merkle Tree를 고려했다. 하지만 이는 위의 특성 중 오버헤드가 적어야 한다는 것과 incremental 하게 만들 수 있어야 한다는 것을 만족시키지 못했다.

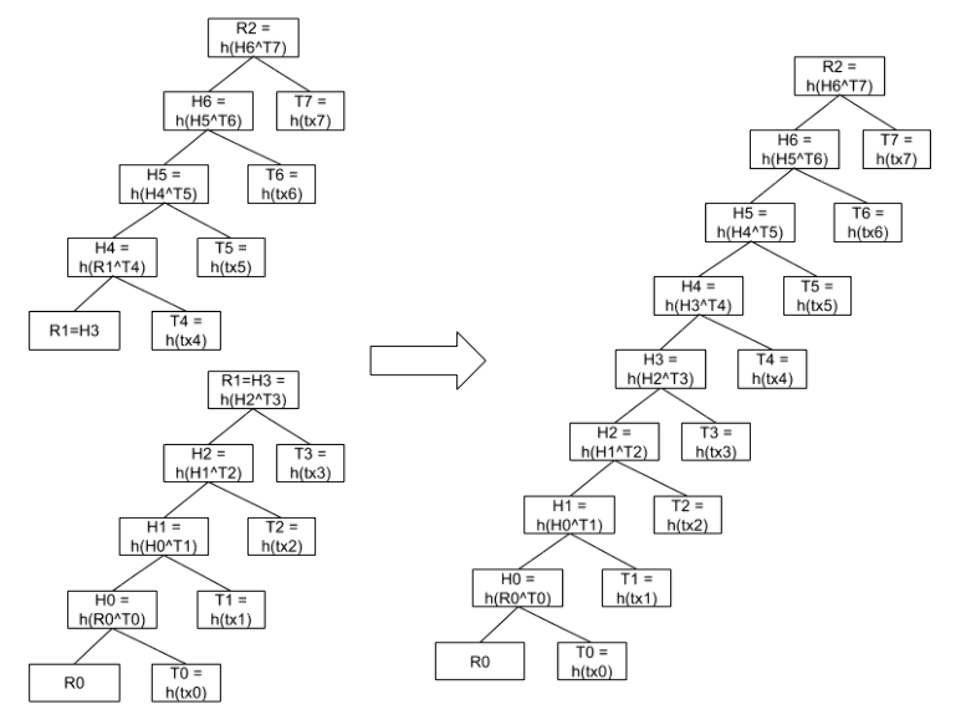
그래서 우리는 왼쪽으로 치우친 Skewed Merkle Tree를 사용하기로 결정했다. Skewed Merkle Tree에서는 전 블록의 root위에 현재 블록의 트랜잭션들을 이용해 새 tree를 만들어 지금까지 실행된 전체 트랜잭션 목록을 담는 해시를 빠르고 가볍게 생성할 수 있다. 즉, 전체 트랜잭션 목록을 incremental 하게 만들 수 있고, 만드는데 드는 시간과 메모리는 트랜잭션 수에 선형적으로만 비례한다. 게다가 우리가 관심있는 것은 검증을 위한 root값 뿐이기 때문에 사용하는 메모리는 트랜잭션 개수와 상관없이 상수배만큼 사용하도록 최적화할 수 있다. 실제로 코드체인에서 사용한 코드는 다음과 같이 간단하다.
물론 Skewed Merkle Tree도 만능은 아니다. Skewed Merkle Tree는 Merkle Tree의 기본적인 기능인 Merkle path를 만드는 데 비효율적이다. 따라서 Merkle path를 만들어야 하는 경우 Skewed Merkle Tree보다 고전적인 balanced Merkle Tree가 더 적절하다. 하지만 코드체인이 transactions_root와 invoices_root를 사용하는 용도를 고려해봤을 때, Merkle-proof path를 사용하지 않는다. 오로지 데이터의 검증을 위해서만 사용하기 때문에 Skewed Merkle Tree가 더 적절하다고 판단했다.
CodeChain 소스코드는 github repo에서 확인 가능합니다. 개발자간 실시간 소통을 위해 gitter channel도 운영중이니 들어오셔서 자세한 문의도 하시면 됩니다.
Originally published at blog.seulgi.kim on June 15, 2018.
 가입하기
가입하기