
Google Cloud Next ‘19의 두번째 날은 Product Innovation Keynote로 시작하여 축제로 마무리 되었습니다. 참석한 세션들의 대부분이 머신러닝에 대한 내용이었던 것을 보면 AI의 시대가 성큼 다가오는 것을 느낄 수 있었습니다.
목차
- Product Innovation Keynote
- What’s New with BigQuery ML and Using it to Assess Data Quality
- Data Warehousing With BigQuery: Best Practices
- Opening the Doors to ML: How AAA Leverages BQML and Google Sheets to Predict Call Volume
- Automating Visual Inspections in Energy and Manufacturing with AI
- 맺음말
Product Innovation Keynote

그림 1. Product Innovation Keynote 행사 전경
2일차 행사는 Google 클라우드의 신규 서비스 및 기능에 대해 소개하는 키노트로 시작되었습니다. 키노트에서 소개된 주요 내용은 아래와 같습니다.
- Anthos에 포함된 기능들에 대한 추가 해설
- Traffic Director: 하이브리 클라우드 운영 시에 활용할 수 있는 트래픽 분배기
- Cloud Run: 오픈 소스 프로젝트 KNative 기반의 서버리스 환경
- Natural Language API & AutoML Natural Language
- 콜센터 등에 사용할 수 있는 자연어 이해 API 서비스 베타 오픈
- 보안
- Google은 보안을 매우 중요하게 생각한다는 점에서 “Security first, everything else will follow”라는 표현을 사용
- 보안 관련 수백 개의 피쳐가 Next ‘19 행사에서 소개 되는 중
- 개인정보 보호를 위한 Data Loss Prevent
- 해킹 감지를 위한 Event Threat Detection API
- Microsoft 서버 제품이 Google 클라우드에서 포함됨
- Cloud SQL에서 SQL Server를 추가로 지원
- Cloud Active Directory 서비스 오픈
- 빅 데이터 분석
- Cloud Data Fusion: BigQuery ETL과 스케쥴링 등을 UI 로 간편하게 처리
- BigQuery BI Engine: Tableau 등의 BI 툴에서 매우 빠르게 BigQuery 데이터에 접근
- BigQuery 커넥티드 시트: Google 시트에서 대용량의 데이터 다룰 수 있게 됨
- AutoML Tables: 숫자, 클래스, 문자열, 타임스탬프, 목록 같은 다양한 테이블 형식의 데이터 기본 요소를 자동으로 처리하며 누락 값, 이상점, 기타 일반적인 데이터 문제를 감지하고 처리하도록 지원함
- Data Catalog: 빅 데이터에 대한 사전 검색 서비스
- Dataflow의 새 피처
- Dataflow SQL: 선점형 VM을 이용한 Dataflow에 대한 유연한 스케줄링
- Cloud Composer: Apache Airflow를 Google 클라우드 매니지드 서비스로 제공
What’s New with BigQuery ML and Using it to Assess Data Quality
이번 세션은 BigQuery ML에 대한 개요와 신규 피쳐에 대한 소개, 호텔 예약 서비스인 Booking.com이 BigQuery ML을 사용하여 데이터 품질은 높은 이야기로 구성되었습니다.

그림 2. Booking.com의 BigQuery ML 사례 발표
BigQuery ML이란 BigQuery 콘솔 상에서 SQL로 머신러닝을 돌리는 기능입니다. BigQuery ML은 GA(General Available) 상태로 공개되어 누구나 사용할 수 있게 되었습니다. 이번에 함께 공개된 피쳐는 다음과 같습니다.
- 모델 평가 시각화 차트 UI
- k-평균(k-means) 클러스터링
- 행렬 인수분해(Matrix Factorization)
- Tensorflow를 이용한 DNN(Deep Neural Network)
- Tensorflow 모델 임포트
- 전처리 함수

그림 3. 모델 평가 시각화 차트 UI
행렬 인수분해 기능은 넷플릭스의 영화 추천과 같은 제품 추천, 그리고 그룹 추천, 오퍼 매칭에 사용할 수 있습니다. 유저, 아이템, 레이팅을 입력값으로 적절한 추천 결과를 도출할 수 있습니다.
DNN은 로지스틱 회귀에 비해 훨씬 높은 적중률을 보였습니다. 예를 들어 Arburn과 UNC가 경기했을때, 3점슛 시도가 얼마나 나올지 예측하는 시험을 했을 때 로지스틱 회귀는 27%, DNN은 72%의 적중률을 보였습니다.

그림 4. DNN과 로지스틱 회귀를 이용한 예측 결과 비교 사례
Tensorflow 모델 임포트는 텍스트 또는 이미지 같은 비선형(non-linear) 모델에 사용할 수 있습니다. GCS에 올린 Tensorflow 모델 파일을 사용하는데, 1개의 입력에 대해 1개의 출력만 가능하기 때문에 RNN 또는 LSTM은 불가합니다.
전처리 함수를 지원하여 모델 만들 때 피쳐 변환을 할 수 있으므로 모델 작성자와 사용자가 같은 변환을 두번 작성할 필요 없어졌습니다. Bucketize 등과 같은 일반적으로 자주 사용되는 전처리 함수는 기본 제공하고 있습니다.
BigQuery와 텐서플로우 DNN 모델로 이미지 분류기 만든 데모를 시연했습니다. 이미지를 선택하면 비슷한 이미지를 검색해서 찾아주는 기능을 SQL만으로 구현했습니다.

그림 5. BigQuery ML을 활용한 이미지 검색 데모
k-평균 클러스터링은 고객 세그먼트를 만들거나 데이터 퀄리티를 평가할 때 사용할 수 있습니다. 클러스터의 수와 거리 등의 옵션을 선택할 수 있습니다.
이어서 Booking.com의 사례가 소개되었습니다. Booking.com의 전세계 호텔 예약 서비스는 호텔 방(room) 검색 페이지 왼쪽에 “호텔 방 시설” 옵션을 선택할 수 있는 필터가 있습니다. 호텔을 검색하는 사람 마다 선호하는 시설이 있기 때문에 자주 사용되는 기능입니다. 예를 들면 뷰가 좋은 방, TV 가 있는 방, 부엌이 있는 방과 같은 편의시설의 유무에 대한 옵션, 그리고 브라이덜 스위트와 같은 방의 유형을 선택할 수 있습니다.
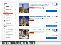
그림 6. Booking.com 사이트의 호텔 방 시설 옵션
이 필터 옵션은 176개로 데이터 품질이 높이기 위해 많은 노력이 필요했습니다. 예를 들면 “평면 TV”는 있는데 “TV”는 없는 방이 발견되었습니다. 담당자들은 이런 오류를 찾아서 수정하였습니다. 필더의 데이터 품질, 즉 신뢰성이 떨어지는 문제는 고객과 호텔 양측면에서 문제를 유발합니다. 고객 입장에서는 해당 옵션을 보고 예약을 했는데 실제 숙박했을 때 없다면 매우 부정적인 경험을 하게 될 것이고, 호텔 입장에서는 시설을 Booking.com에 등록하는 과정에서 누락하면 고객의 선택에 부정적인 영향을 미칠 것입니다.
처음에는 데이터 품질의 문제를 AI 없이 룰 기반으로 해결하려고 시도했으나, 방의 유형은 10만개 이상으로 필터 옵션 176개와 조합되어 매우 커진 데이터셋을 처리할 방법을 찾지 못했습니다. “평면 TV”, “채널 마다 과금” 같은 옵션은 “TV”가 없으면 불가능한 옵션인데, 이런 관계를 데이터로서 관리하는 것은 불가능에 가까웠습니다. 옵션이 수동으로 입력되는 방식이고 매일 업데이트 되고 있기 때문에 더욱 그렇습니다.

그림 7. ML 클러스터링 또는 k-평균에 대한 경험을 묻는 발표자와 그렇다고 손을 든 대다수 청중
하지만, 이 사례는 항목들을 그룹으로 묶고 그외 특이점(outlier)들을 구분하면 비정상을 색출할 수 있다고 전제하고, 데이터의 전반적인 품질은 양호하며 각 항목은 해당 기능에 따라 정확하고 완벽하게 설명된다고 가정할 수 있었습니다. 이는 ML을 사용하기 적합한 케이스입니다.
176개 옵션에 대한 방의 유형을 정의하는데, 각 옵션에 대해 참, 거짓으로 구분되는 칼럼을 만듭니다. 이에 따라 경우의 수를 클러스터로 만들면 176차원의 데이터셋이 만들어집니다. k-평균은 2차원에서 클러스터링으로 거리가 비슷하게 모여있는 점들을 클러스터로 정의하고 레이블을 달아주는데, 클러스터에서 벗어니면 특이점이라고 판단할 수 있습니다.
어떻게 하면 방의 유형을 2차원 차트로 시각화 할 수 있을까요. x 축은 “채널마다 과금” 여부, y 축은 “TV” 여부, 이런 식으로 4개 축을 추가해서 x, y, z, a, b, c 축을 정의하면 6차원 차트가 그려집니다. 실제로 6개 옵션만 추출해서 클러스터를 위한 차원을 그려본 뒤에, 다시 15개 옵션으로 시각화 작업을 수행했습니다. 그러나 15 차원의 처리만으로 작업자의 데스크탑 PC는 뻗었습니다. 그런데 176 차원의 데이터는 어떻게 처리할 수 있을까요. 데스크탑 PC에서는 불가능하고 그래서 클라우드가 필요했습니다.
앞서 설명한 바와 같이 비슷한 방의 유형은 클러스터를 구성합니다. 예를 들면 “화장실이 있는 방” 클러스터에는 ‘화장실, 샴푸, 수건, 평면 TV’가 있는 방도 있고 ‘화장실, 샴푸, 수건’이 있는 방도 있습니다. 이러한 클러스터를 N개 생성해서 튀는 데이터 군을 색출합니다. “평면 TV”가 있는 방은 대부분 “TV”도 있다고 나옵니다. 따라서 “평면 TV”가 있는데 “TV”가 없다면 잘못된 데이터라는 것을 알 수 있습니다.
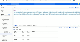
그림 8. 러신러닝을 실행하는 실제 SQL
아래 그림과 같이 클러스터링 결과를 Data Studio에서 보니 10번 클러스터가 중앙에서 멀리 떨어져 있었습니다.

그림 9. Data Studio를 이용해 시각화 한 클러스터링 결과
해당 클러스터를 클릭하여 상세 내용을 조회했습니다. 10번 클러스터 중에 가장 멀리 떨어져 있는 한 점을 샘플로 하여 내용을 보니 ‘변기, 샤워, 샴푸, 바디워시’는 있지만 ‘화장실’이 없었습니다. 이는 말이 안되는 데이터이며, 잘못된 데이터 하나를 검출하는데 성공한 것입니다.
부킹닷컴은 BigQueryML과 관련하여 다음과 같은 계획을 갖고 있습니다.
- 자동화
- 이 프로세스를 매일 실행
- 머신러닝을 위한 하이퍼 파라미터 정의
- 데이터 탐색을 위해 객실을 구분할 수 있는 항목을 발굴
- A/B 테스트
- AI로 자동 보정된 필터와 기존 필터를 보여주고 설문조사를 하여 AI의 성과를 검증
- 발전
- 사용자가 선호하는 항목이 무엇인지 발굴
더 자세한 내용은 부킹닷컴 기술 블로그 https://blog.booking.com/ 사이트에 공개되어있습니다.
Data Warehousing With BigQuery: Best Practices

그림 10. ELT / ETL 모범 사례를 발표하는 전경
이번 세션은 Google의 데이터 엔지니어가 BigQuery를 이용해 데이터웨어하우스를 구축하면 어떤 이점이 있는지, 그리고 모범 사례는 무엇이 있는지에 대해 소개하였습니다.

그림 11. 전통적인 DW와 BigQuery의 비교
BigQuery의 구조는 대규모 분산 저장소와 드레멜 엔진을 이용한 대규모 분산 컴퓨팅 자원으로 구성됩니다. 둘 간의 통신은 페타비드 네트워크로 연결되어 혁신적인 속도를 구현했습니다.

그림 12. BigQuery 아키텍쳐
또한 빅쿼리의 메모리는 대형 원격 메모리 셔플 구조로 워커가 죽어도 다른 워커가 처리 중이던 공유 메모리에 접근할 수 있어 고가용성을 확보하였습니다.

그림 13. BigQuery의 원격 메모리 셔플 동작에 대한 개념도
데이터를 가져오거나 내보낼 때는 압축된 JSON 형식이 가장 느리고 압축된 Avro 형식이 가장 빠릅니다.

그림 14. BigQuery의 데이터 포맷 간 속도 비교
ELT 또는 ETL의 경우 람다 아키텍처를 모범 사례로 언급하였습니다. 스트리밍 데이터인 경우 PubSub – Dataflow – BigQuery 순으로 처리하고, 배치 데이터인 경우 GCS – Batch Load – BigQuery 순으로 처리합니다. ETL 보다는 데이터의 원본을 그대로 저장하고 BigQuery에서 변환하는 방식인 ELT를 추천하였습니다.

그림 15. ELT / ETL 플로우
스키마 디자인은 가급적 역정규화를 하여 테이블 간의 조인을 회피할 것을 권고하였습니다. 이를 위해서는 다음 사항을 고려해야 합니다.
- BigQuery만의 Nested, Repreadted 필드의 이점을 활용
- 세션 이벤트 저장
- 순서가 있는 데이터 저장
- 국가, 지역, 날짜와 같이 자주 변하지 않는 데이터는 그대로 포함
- 쿼리를 단순화
고객 사례를 보면 77개 테이블을 쿼리로 조인하여 기대한 성능을 내지 못한 사례가 있었습니다. 또한, 더 큰 성능 향상을 위해서 파티셔닝을 이용하는 것도 좋습니다.

그림 16. BigQuery의 파티셔닝 동작에 대한 개념도
클러스터터 필드를 이용하는 것도 성능을 향상시킬 수 있는 좋은 방법입니다. 클러스터 필드는 최대 4개까지 지정할 수 있으며, PK 같은 필드에 사용하는 것이 대표적인 예입니다.

그림 17. BigQuery의 클러스터 동작에 대한 개념도
BigQuery는 할당된 슬롯으로 리소스를 관리하는데, 사용 가능한 모든 슬롯을 사용하게 되어있습니다. 예를 들어 2000 슬롯을 할당되어있을 때 2개의 작업이 수행되면 각 1000개의 슬롯을 사용하게 됩니다.

그림 18. BigQuery의 스케줄러 동작에 대한 개념도
중요한 쿼리를 실행할 때는 다른 쿼리가 영향을 미치지 않도록 슬롯 예약(Slot Reservation) 기능을 이용해 우선 순위를 할당하는 것이 좋습니다.
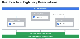
그림 19. BigQuery의 슬롯 동작에 대한 개념도
데이터 접근권한에 대해서는 사용자 유형별로 Google 프로젝트를 별도로 생성하여 권한을 관리하는 것이 좋습니다.
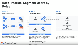
그림 20. 역할에 따른 사용자 구분
데이터웨어하우스 관리자라면 데이터 스튜디오를 이용해 쿼리 비용과 부하를 모니터링하는 것이 좋겠습니다.
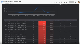
그림 21. BigQuery 관리를 위한 데시보드 구성 예시
발표자는 Hadoop 기반에서 Google 클라우드 기반으로 전환한 Tead 사의 ELT 사례를 소개했습니다. Tead 사는 BigQuery로 전환해서 다음과 같은 이점을 얻었습니다.
- 대용량의 데이터를 빠른 속도로 처리
- 데이터 접근성
- NoSQL 기반인 Cassandra에 비해, 모두가 익숙한 SQL을 이용해 데이터 분석을 쉽게 수행할 수 있음
- 주피터 노트북을 이용할 수 있음
- Google 권한 체계로 접근 권한에 대한 관리가 용이함
- 빅 데이터 서버 관리에 인력과 시간 투자가 불필요

그림 22. Teads 사의 BigQuery 도입 효과
Opening the Doors to ML: How AAA Leverages BQML and Google Sheets to Predict Call Volume
이번 세션에서는 종합 설비 유지보수 회사인 AAA 사의 담당자가 BigQuery ML에 대한 소개와 이를 이용한 고객센터 통화 건수를 예측한 사례를 발표했습니다. AAA 사는 BigQuery ML을 이용해 쉽게 머신러닝 기반의 제품을 개발할 수 있었습니다. 커스텀 모델의 개발을 위해 기존에 7단계 작업이 필요했던데 비해 3단계의 작업만 필요하게 되었습니다.

그림 23. 커스텀 모델 개발을 위한 단계 비교
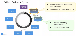
그림 24. BigQuery ML의 업무 절차
AAA 사는 고객이 1000만 명으로, 세션 참석자 대부분이 AAA의 회원이었습니다. 자동차 부문만으로도 5개 콜센터에 상담 직원이 3000명의 직원이 연간 1500만 건의 통화를 하고 있습니다. 자동차 보험 처리 및 정비에 대한 고객의 전화는 즉시 응대해야 합니다. 업무 효율화를 위해 10개월 간 모든 콜센터의 로그 데이터를 Google Cloud Platform에 수집하여 데이터 레이크를 구축했습니다.
AAA 사는 웹 사이트 또는 챗봇 등 자동화된 시스템도 운영하고 있지만, 일반 전화를 이용하는 고객도 여전히 많습니다. 따라서 즉각 응답을 할 수 있도록 충분한 인원의 직원을 고용해야 하는데, 적정 수준을 초과하면 비용 문제가 발생합니다.
통화 건수를 예측하여 적정 인원의 직원을 고용하는 것이 머신러닝으로 해결하고자 하는 문제였습니다. 고객이 전화를 했을 때 즉각 상담을 할 수 있도록 하려면 어느 정도의 직원이 필요한지를 알고 싶었습니다. 그래서 통화 건수를 예측하기 위해 BigQuery, App Script, Google 시트를 활용했습니다.

그림 25. AAA사에서 활용한 솔루션
위 3개의 제품만으로 문제는 해결되었습니다. Google 시트 내에서 AppScript을 이용해 버튼을 누르면 BigQuery를 호출해서 예측 작업을 수행하게 했습니다.

그림 26. Google 시트 내에서 AppScript를 이용한 BigQuery 동작 예시
Automating Visual Inspections in Energy and Manufacturing with AI
이번 세션은 미국 에너지 회사 AES 사와 국내 회사 LG CNS 사의 사례 발표였습니다. Google 클라우드 머신러닝 제품을 사용하여 현업 생산성을 올린 사례를 소개했습니다.

그림 27. LG CNS에서 발표 중인 전경
비전 기반의 머신러닝은 공장 등 실제 산업현장에서 이미 활용되고 있습니다. Google에서 제공하는 이미지 처리 머신러닝 서비스는 API와 AutoML 두 가지가 있습니다.

그림 28. Google에서 제공하는 두 가지 머신러닝 제품 유형
AutoML Vision은 Google 콘솔에서 사용자가 이미지 업로드 하면, 이미지의 객체 탐지까지는 자동으로 처리하고, 탐지된 객체에 사용자가 분류 및 라벨링 하면서 학습을 진행하게 됩니다.
AES 사는 풍력발전소 유지보수 업무를 위해 드론과 Google Cloud Platform을 활용해 발전기의 크랙을 자동으로 탐색하였습니다. 이를 통해 산업재해 위험이 높은 작업을 57,000 시간 절감하였고, 10억의 비용을 절감했습니다.

그림 29. AES 사의 머신러닝 적용 사례
이 프로젝트를 위해 6명의 직원이 Google ASL 프로그램을 통해 4주 간의 훈련을 받고 시작했기 때문에 시행착오로 인한 비용을 감소하였습니다.

그림 30. AES 사의 Google ASL 프로그램 참여
LG CNS는 LG 계열사에 IT 솔루션을 제공할 때, Google 머신러닝 제품을 활용했습니다.
그림 31. LG CNS의 AI 관련 업무 소개
LG 디스플레이 등 공장 내 QA 과정에서 자동화된 불량품 검출을 위해 IoT 센서와 딥러닝을 활용했습니다. 이를 통해 QA 품질을 향상시키고, 생산성을 향상시켰으며, 비용을 절감했습니다.

그림 32. 공장 내 품질 검사의 AI 적용 후 변화
LG CNS는 자체 AI 플랫폼이 있었지만 다음과 같은 문제가 있었습니다.
- 인력 문제
- AI 기술자의 채용이 어렵고, 퇴사자가 발생하면 이로 인한 업무 차질이 불가피했습니다.
- 생산성 문제
- 새로운 AI 모델을 개발하는데 많은 시간이 필요했고, 여러 공장과 제품에 적용하기에 인력이 부족했습니다.
- 최적화 및 배포 문제
- 실시간 서비스를 할 수 있는 성능을 내기 위해서는 더 많은 시간과 비용이 소모되었고, 현업 공장에 실제 사용하기 위한 작업에도 상당한 비용이 발생했습니다.
- 또한, 연구 및 테스트 시에도 대규모 컴퓨팅 파워가 필요한데, 실제 서비스를 위해서도 서버를 사용하면서 서버 관리에 대한 복잡도가 크게 증가했습니다.
이런 문제를 해결하기 위해 Google의 AutoML을 도입하였고, 그 결과로 7일 걸리던 모델 개발이 2~9시간으로 단축되었고, 정확성이 기존 대비 6% 향상되었습니다.

그림 33. AutoML을 적용한 효과
이후 AI 기술자들은 생산성이 향상된 만큼 데이터 품질을 향상시키는데 집중할 수 있게 되었습니다.

그림 34. AutoML을 적용한 후 직원들에게 미친 영향
결과적으로 LG CNS 사는 자체 AI 플랫폼과 함께 하이브리드 형태로 사용 중이며, 이 방식으로 수천 개의 AI 모델을 개발하여 활용하고 있습니다.
그림 35. LG CNS의 AI 관련 향후 목표
맺음말
2일차 저녁에는 축제가 있었습니다. 샌프란시스코 오라클 파크에서 가수 초빙 행사가 있었고, 이 곳에서는 모든 술과 음식이 무료로 제공되었습니다.

그림 36. 오라클 파크에서 있었던 DTNXT 축제



