쿠팡은 2014년 중순 자체 Experiment Platform 구축을 시작했다. 이 중 가장 중요한 구성요소로는 지표 연산(Metric Calculation)을 꼽을 수 있다. 적시에 인사이트를 제공하여 비즈니스 담당자들이 데이터에 기반한 의사 결정을 내릴 수 있도록 하는데 기여하는 지표 연산 프레임워크는 실제 구축 과정에서 큰 도전 과제를 해결해야 했다. 수십억 열에 이르는 데이터를 빨리 처리하는 동시에 실험을 진행하고 있는 팀이 올바른 판단을 내릴 수 있도록 확실하고 정확한 연산을 제공하는 것이 그 과제였다.
Experiment Platform은 구축 초기 PV와 판매 지표 일부만 1일 1회씩 제공했었다. 하지만 2016년 Spark 프레임워크를 도입하고 실시간 데이터 consumption이 가능해 지면서 (1) 일간 단위보다 더 짧은 주기로 결과물을 제공하고 (2) 주요 지표를 매 15분 마다 연산하면서 실시간에 준하는 주기로 발전시키고 (3) PV와 판매 지표는 매 4시간 마다 업데이트하는 것이 가능해졌다. 2017년, 도메인 별로 정의된(domain-specific) 지표를 추가하여 실험을 통해 실제 해당 도메인이 추구하는 개선사항(benefit)을 보다 잘 진단/평가할 수 있게 되었다. 2018년 현재는 새로운 지표의 정의와 적용에 필요한 인력과 시간을 줄이기 위해 설정가능한 지표 엔진(configurable metric engine)을 구축하고 있다. 이 글을 통해 지표 연산 프레임워크 (Metric Calculation Framework)의 기본 설계와 지금까지의 진화과정을 상세히 공유하고자 한다.
1.0 속도 및 각종 제약(Slow and Limited)
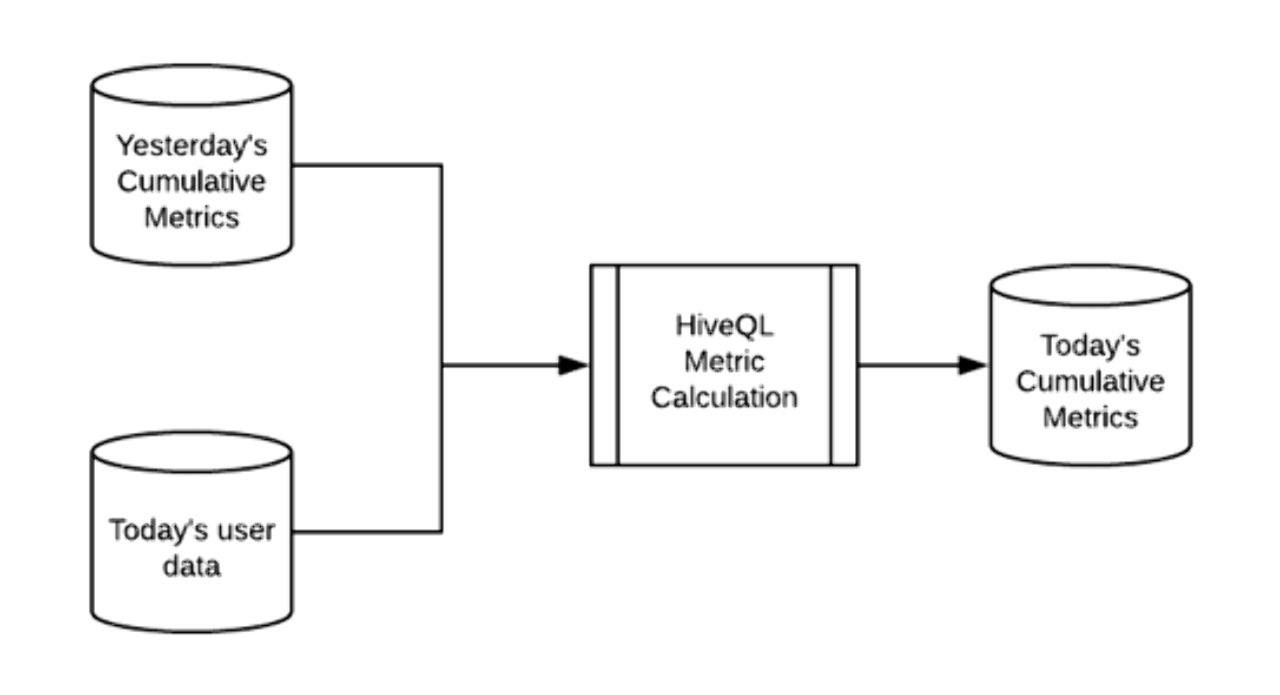
프레임워크 초기에 지표연산은 Hive에서 수행되었다. 당시 연산 속도 개선을 위해서 추가 증분(incremental)에 대해서만 연산을 진행하도록 설계하였다. 즉, 이전 날짜의 누적된 결과는 따로 저장해 두고 일별 연산 작업은 당일 데이터(예: sales transaction, user activities)만 처리한다. 이어 누적된 과거 결과값을 당일의 연산 부분(delta)과 집적하여 당일의 실제 결과값을 생성하도록 했다.

Fig 1. 증분 연산 프로세스: 당일 결과 = 어제 결과 + 당일 데이터
이런 접근법에는 몇가지 제약이 존재했다:
· 연산 속도가 느리고 비용이 많이 들었다. 24개 AB 테스트에 대한 결과 연산 시 약 3시간 정도가 소요되었다.
· 과거의 결과에 대한 의존도가 높아지므로 데이터 보정(correction)에 상당한 비용이 들어갔다. 며칠 전 날짜의 원천 데이터에서 이슈가 발견되거나 코드에 버그가 발생한 경우 해당 이슈가 발생한 날짜로부터 일별 전체 연산 작업을 다시 수행해야 했다. 이로 인해 지표 연산 프레임워크는 그 기간 동안 중단(blocked)될 수밖에 없었다. 즉, 해당 재작업이 완료될때까지 신규 결과에 대한 연산이 진행될 수 없었다.
· 진행 중인 AB 테스트 전체의 지표가 다 연결되어 묶여 있었다. 즉, 특정 이슈가 한 개 혹은 일부 테스트의 하위 테스트에만 영향을 주는 경우에도 해당 테스트에만 제한해서 지표를 재연산하는 것이 불가능했다.
· 데이터 소스 (source)가 제한적이어서 결과를 refresh하는 주기도 제한적이었다. 당일 하루동안의 activity에 대한 결과는 익일 오후 2시가 되어야 제공됐다. 실제 지표 연산 스케쥴은 원천 테이블의 데이터 동기화 스케쥴/주기로 인해 제약이 많았다. 더 자주 업데이트 되는 데이터 소스(source)가 존재했으나 지표 연산에 활용되지 못하는 제약도 있었다.
· 싱글 HiveQL 스크립트 기반의 코드 유지보수도 매우 복잡했다. 쿼리 재사용이 불가했고, 따라서 스크립트의 경우 코드가 수천 줄에 이를 만큼 길어졌으며 이 중 어느것도 unit-test를 진행할 수 없는 구조였다.
위 제약사항들은 쿠팡 개발팀의 개발 사이클에도 큰 장애가 되었다. 개발팀은 빨리 iteration을 진행하기 위해서 일별 수 차례 지표를 업데이트하고 매출에 부정적인 영향은 빨리 feedback을 통해 공유할 수 있는 지표 연산 프레임워크의 개편을 진행하게 되었다.
2.0 속도/확장성/견고성 개선 (Increase Speed, Scale and Robustness)
연산 프레임워크의 재구성을 위한 요건은 다음과 같다:
· SLA
· 각 실험이 시작할 때 treatment(실험군)의 영향도에 대한 빠른 피드백을 얻기 위해 결과의 일부를 15분마다 제공한다.
· 전체 결과는 4시간마다 제공한다.
· 이벤트 (유저클릭, 판매) 발생에서 결과 전달까지의 딜레이를 줄인다
· Scalability
· 지속적으로 증가하고있는 동시 진행 A/B테스트 (200+건)를 지원한다.
· Robustness and fault-tolerance
· 하드웨어 문제가 있는 경우 사람의 개입 없이 연산을 재개한다.
· 연산 에러 (데이터 문제, 코드상의 버그)가 있는 경우 빠르고 쉽게 복구한다.
· 테스트 설정이 잘못된 경우, 테스트 일부에 대해 쉽고 빠른 재연산을 가능케한다.
보다 빠른 처리와 관리 및 테스트가 가능한 코드 베이스를 위해 HiveQL의 대체안으로 Apache Spark를 선택하였다. Spark는 컴퓨터 클러스터상에서 구동되는 큰 스케일의 데이터 분석 어플리케이션을 위한 오픈소스 병렬 처리 프레임워크다.
이러한 기술적인 변경사항과 함께 SLA 및 robustness 요구사항에 맞춰 lambda architecture가 채택되었다:
· Batch layer는 믿을 수 있는 데이터의 원천(source of truth)이 되며 모든 데이터를 정확하고 신중하게 처리한다. 결함 내구성(Fault tolerant)이 있으나 느리다는 단점도 있다. 제공되는 모든 결과는 몇시간 이전의 데이터이다.
· Speed layer는 batch layer의 레이턴시를 보완한다. 마지막 배치 결과와 현재시점 사이의 데이터의 차이를 처리한다. 증분법의 로직을 사용해 보다 복잡하고 속도를 위해 정확도를 떨어뜨릴수 있다.
· Serving layer는 batch 및 speed layer의 결과를 통합하여 결과를 유저들에게 제공한다.
아래의 그림은 언급된 각각의 layer가 지표 연산 프레임워크 상에서 어떻게 구현되었는지에 대해 자세하게 보여준다.

Fig 2. Lambda Architecture

Lamda architecture를 순수하게 추구하는 입장에서 보자면 batch layer는 중간 단계의 데이터셋을 유지(persist)하는 대신 모든 미가공 input 데이터를 매시간 처리하여 최상의 시스템 robustness를 보장하도록 제안한다. 코드상의 버그 혹은 데이터 이슈가 있을 경우 수정 후 batch layer를 구동시켜 데이터를 처음부터 처리해 가장 정확한 결과를 보장하기 위해서다. 그러나, 초기 성능 테스트 결과 Spark (당시 버전 1.5)로는 10억대의 데이터셋을 효율적으로 join할 수 없었다. 따라서 SLA 및 확장성 요건에 따르기 위하여 절충안이 나올 수 밖에 없었다: 일별 중간 데이터셋이 유지되었다.
아래 Fig.3은 사용되는 data aggregation level을 보여준다. Input 데이터는 테스트와 관계 없이 유저 레벨에서 사전 aggregation이 이루어진다. 해당 데이터는 일별 테스트 레벨의 지표 산정을 위하여 각 테스트에 재사용 될 수 있으며 일자 및 테스트 레벨로 저장된다. 누적 지표는 전체 테스트 기간 동안 합산된 일별 테스트 레벨 데이터를 통해 산정된다.

Fig 3. Data Aggregation Levels
더 많은 A/B 테스트를 동시에 지원한다는 것은 처리할 데이터 사이즈도 함께 증가한다는 뜻이다. 데이터 사이즈는 Spark 성능에 큰 영향을 미친다. 지표 연산 프레임워크는 모든 테스트 데이터를 한꺼번에 처리하는 대신 데이터를 분할(divide)한 뒤 분할된 데이터를 하나씩 처리한다. 다시 말해 각각의 테스트를 독립적으로 처리함으로서 데이터 사이즈를 안정적으로 가져가고 (join 사이즈는 더 이상 실제 active AB test 숫자에 비례하여 늘거나 줄지 않는다.) 처리 후에는 다시 데이터 크기를 Spark의 안전 수준인 백만 범위대로 다시 복구한다.
200 tests x 15 days x 4 million exposure logs / day = 12 billion logs to process
> 1 test x 15 days x 4 million exposure logs / day = 60 million logs
마지막으로 Spark의 리소스를 최대한 활용하고 성능을 높이기 위해서 개별 테스트 데이터 처리는 Akka actor 프레임워크를 이용하여 병행으로 이루어진다. 아래의 Fig 4는 병행 job 시퀀스를 상세하게 보여준다. Master actor가 테스트 정보를 불러와 Worker actor pool을 생성한 후 테스트 별 1개 메시지를 Worker actor 풀에 전송한다. 각각의 메시지는 간단한 round-robin 방식으로 각 Worker actor에 배정된다. Worker fail시에도 다른 테스트들은 프로세싱이 지속된다. Fail 한 테스트는 job의 마지막 단계에 리포팅 되고 fail한 테스트에 한해 job이 재실행 된다. 이런 병행 프로세싱은 연산 시간을 대폭 감소시키고 테스트 단의 failure를 독립시킬 수 있다 (다시 말해서 단일 테스트가 실패한다고 다른 모든 테스트 프로세싱이 방해받는 일은 없다.)

Fig 4. Parallel Spark Job Sequence
상기 구조 변경(re-architecture)을 통해 지표 연산 프레임워크는 합의된 SLA 기준을 모두 충족하게 되었다:
· Batch layer는 4시간 안에 전체 데이터를 처리하며, 수백개에 달하는 A/B 테스트 결과를 14시간이 아니라 5시간 내에 전달
· Speed layer는 결과의 일부분을 매 15분 마다 제공하며, 지연은 25분 정도만 소요
2.1 클라우드로 / Moving to Cloud
2017년, 쿠팡은 on-premise 데이터 센터에서 클라우드 환경으로 시스템 이전을 완료했다. 동시에 데이터 스토리지도 HDFS에서 S3로 전환 했다. 클라우드 이전과 함께 지표 연산 프레임워크는 다음과 같은 두 가지 큰 변화를 겪었다:
Spark 1.5가 2.1로 업그레이드 되면서 마침내 Tungsten 활용이 가능해졌다.
Hive Metastore를 거치지 않고 S3에 직접 데이터 조회와 입력이 가능해 졌다. Hive Metastore에 대한 job 의존성이 없어지면서 I/O 속도 뿐 아니라 데이터 신뢰도가 크게 개선되었다.
이런 변화 덕분에 지표 연산 시간은 4시간에서 1.5시간으로 60% 이상 단축되었다.
3.0 도메인 별 지표 연산 엔진 / Domain-Specific Metric Calculation Engine
표준화된 PV 지표와 일반적인 판매 지표만으로는 실무 팀들이 의사결정을 내리는 데 필요한 인사이트를 충분히 제공하기 힘들었다. 통상 개별 A/B 테스트는 쿠팡의 전사 판매 지표에 미치는 영향이 매우 적기 때문에 팀들은 특정 로컬 지표를 향상시키는데 집중한다. 예를 들어 쿠팡 검색팀의 경우 신규 검색 알고리즘을 구현해 조회된 검색 결과의 relevancy 향상을 도모하고자 했다. Relevancy 여부는 해당 검색 후 유저가 클릭을 했느냐에 기반해서 판단한다. 예를 들어 Ratio of Searchers with Click (클릭을 동반한 검색 비중)과 같은 새로운 검색 도메인만의 지표를 도입함으로써 신규 알고리즘과 기존 알고리즘 간의 비교분석이 가능해지는 것이다.
도메인별 고유 지표 추가를 용이하게 하기 위해 관심사의 분리(SoC — Separation of Concern) 원칙이 적용되었다
· 도메인 팀은 해당 비즈니스 로직을 담당하며 신뢰할 수 있는 데이터 원천(Source of Truth)을 표준화된 event data format으로 집적하는 작업을 담당한다.
· Experiment Platform팀은 범용(generic) 지표 엔진을 담당하며 해당 엔진은 취합된 이벤트 데이터를 input으로 받아서 sum(총계)/count(총 수)/distinct count(중복 없는 고유 count)/두 개 지표의 비율과 같은 configuration(설정)을 기반으로 개별 이벤트에 특정 aggregation operation을 적용해 지표를 연산한다.

Fig 5. Event-based Metric Calculation Process
4.0 — 향후 과제/ The Next Chapter
이 글은 Hive기반의 일별 주기 연산에서 시작하여 Spark기반의 batch 및 실시간 다이나믹 프로세싱 엔진을 탑재하고, 이어 Spark 기반의 도메인 별 지표 엔진 구현에 이르는 Experiment Platform의 지표 연산 프레임워크 진화 과정에 대해 상세히 다루었다. Experiment Platform은 혁신을 지향하며 지표 연산 능력의 지속적인 향상을 추구한다. 현재 우리 팀은 차세대 지표 엔진을 구축하고 있다. 신규 엔진은 더욱 고도화된 configuration 활용을 통해 이벤트 생성과 신규 지표 추가에 걸리는 노력을 줄여 줄 것이다. 2018년 하반기 신규 엔진을 실제 운영환경에 출시한 뒤 관련된 상세 내용을 공유할 예정이다.

Beibei Ye, Director, Software Engineering / Isabelle Phan, Principal, Software Engineering
 가입하기
가입하기