-
프롤로그
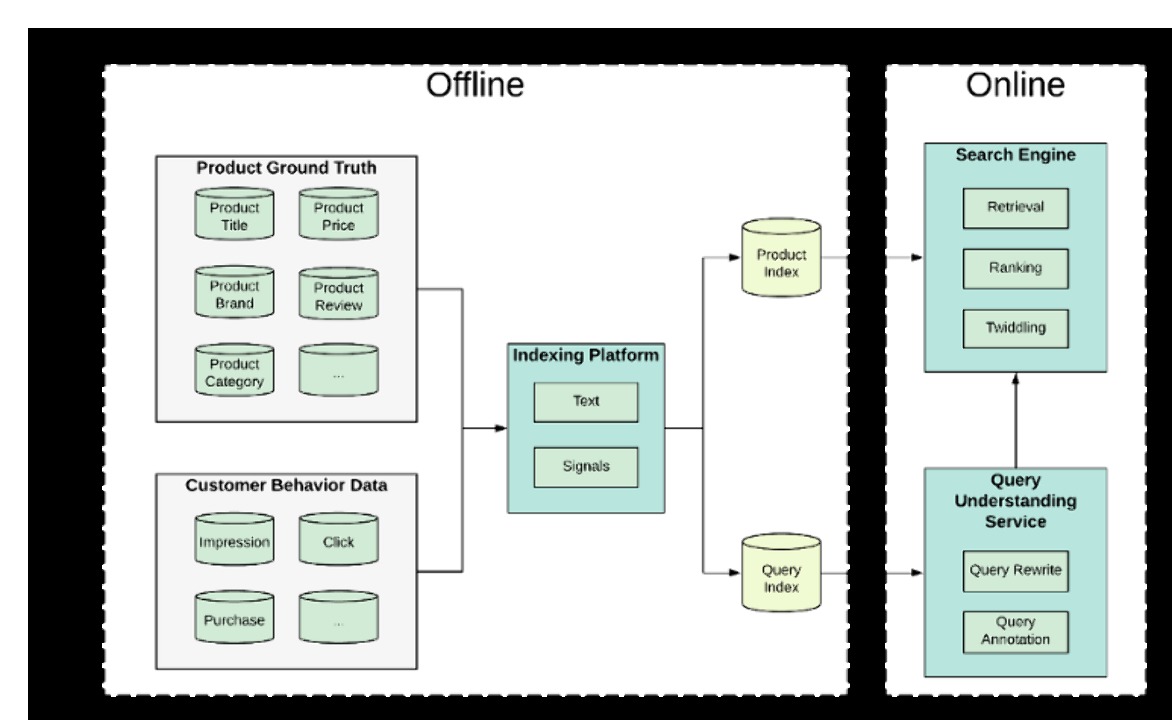
검색은 고객이 쿠팡에서의 여정을 시작하는 주요 통로다. 검색 경험은 고객이 ‘쿠팡 없이 어떻게 살았을까?’ 라고 묻는 세상을 만들기 위해, 쿠팡이 달성해야 하는 미션의 핵심이다. 쿠팡 검색엔진의 목표는 고객 검색 키워드를 기반으로 최고의 프로덕트(연관상품, 랭킹, 상품평, 가격, 브랜드)를 제공하는 것이다. 관련성(relevancy)이 가장 중요한 구글과 같은 전통적인 웹 검색엔진과는 달리, 쿠팡은 고객이 관심을 갖는 랭킹,상품평, 가격, 브랜드 등의 요소도 중시한다. 이들 요소들은 모두 검색과 랭킹에 영향을 미친다. 본 글에서는 쿠팡의 전반적인 검색 작동 및 검색 색인 구축 기제에 대해 중점적으로 살펴보기로 한다.
검색 아키텍처 개요

검색 엔진은 검색 요청을 받은 후, 하기와 같은 절차를 거쳐 최상의 검색 결과들을 찾아낸다.
검색어(query) 이해. 고객의 검색 의도 및 카테고리/브랜드와 같은 부차적인 단어(query annotation) 파악
검색. 검색어와 상품 텍스트 정보를 기반으로 대응하는 후보 상품군 검색
랭킹. 랭킹 함수 또는 기계학습(ML) 모델을 적용하여 후보 상품들의 순위 도출. 랭킹 함수는 일반적으로 랭킹 시그널을 입력 정보로 사용하여 각 후보 상품의 점수를 반환함. 점수Score = Func (텍스트 관련성 시그널, 순위 시그널, 상품평 시그널, 가격 시그널…)
트위들링(Twiddling). 프로모션과 같은 비즈니스 로직에 따라 결과 조정
인덱싱 플랫폼은 검색 및 랭킹에 필요한 모든 데이터를 제공한다. 모든 소스 데이터를 통합하여 검색 엔진을 위한 검색 인덱스를 생성한다.
검색 경험을 향상시키기 위해서는 랭킹 알고리즘이 핵심이다. 따라서, 우수한 검색 플랫폼이라면 랭킹 알고리즘의 신속한 이터레이션(iteration)을 지원해야 한다. 랭킹 엔지니어에게 있어 새로운 랭킹 알고리즘 구축에 필요한 데이터를 구하는 것이 첫 번째 직면하는 도전일 것이다. 엔지니어들은 어떻게 이들 상품 데이터 및 고객 행동 데이터에서 랭킹 특성(feature)을 쉽게 추출해 낼 수 있을 것 인가? — — 바로 인덱싱 플랫폼이다!
인덱싱 플랫폼은 검색엔진이 검색 및 랭킹에 필요한 모든 데이터를 제공해 주는 토대이자 공장인 것이다.
인덱싱 플랫폼 개요

인덱싱 플랫폼은 서로 다른 원본 데이터(ground truth) 테이블에서 데이터를 수집하고, 상품/검색어 기반으로 입력된 데이터를 비정규화하며, 검색 엔진 인덱스를 구축하는 역할을 수행하는 확장 가능한 플랫폼이어야 한다. 아울러, 랭킹 엔지니어가 랭킹 시그널을 더 쉽게 개발할 수 있도록 프레임워크를 제공해야 한다.
1단계: 인덱싱 플랫폼 0.1

초창기 쿠팡의 보유 상품 수는 많지 않았다. 쿠팡은 대부분의 원본 데이터(ground truth)를 가격, 브랜드, 카테고리 등과 같은 관계형 데이터베이스에 저장했다. 인덱싱 플랫폼의 첫 번째 버전은 관계형 데이터베이스들의 SQL 엔진을 활용하여 상품 키로 여러 테이블을 조인하여 이를 하나의 비정규화된 테이블에 통합하였다. 그 후, 비정규화 테이블의 데이터를 온라인 서빙 검색 클러스터에 전달하여 다이나믹 인덱스를 만들었다. 이로써 검색 엔진은 상품의 텍스트 정보와 몇 가지 간단한 시그널에 기반한 기초 랭킹을 바탕으로 기본적인 검색 기능을 제공할 수 있었다. 그러나 상품 수가 빠르게 증가하면서 많은 문제가 발생했고, 인덱싱 시간이 길어지고 서비스도 불안정해졌다. 분명 시스템의 문제였다.
이는 전혀 플랫폼이 아니었다! 원본 데이터와 온라인 서빙 검색 클러스터 사이의 커넥터에 불과할 뿐이었다.
더 많은 양의 데이터를 처리하기 위한 확장이 불가능했다.
관계형 데이터베이스는 수십 개의 대형 테이블을 조인하는 과정에서 느리고 불안정해졌다.
온라인 서빙 검색 클러스터에서 인덱스를 구축하는 것은 상당히 오랜 시간이 소요되며 비싼 작업이다. 각 복제본(replica)은 동일 데이터에 대해 같은 인덱스를 만들어야 하고 이를 위해 막대한 자원이 낭비되었다.
랭킹 엔지니어가 며칠 내에 검색/랭킹 시그널을 추가하는 것은 거의 불가능했다.
Stage 2: 인덱싱 플랫폼1.0

상품 수가 빠르게 증가하면서 기존 설계로는 더 이상 지원할 수 없는 상태에 이르렀고, 우리는 쉽게 확장 할 수 있는 진정한 분산 플랫폼을 만들기 위해 전체 시스템을 재구성하기로 결정했다. 새로운 시스템은 분산 데이터 처리를 위해 널리 사용되는 오픈 소스 플랫폼인 하둡(Hadoop)에 구축되었다. 관계형 데이터베이스가 병목이었기 때문에, 모든 원본 데이터가 관계형 데이터베이스에서 하둡의 데이터 웨어하우스인 하이브(Hive)로 복제되었다. 동시에 랭킹 시그널도 하이브 테이블로 생성되었다. 이로서 검색 인덱스 구축에 필요한 모든 데이터가 하둡 플랫폼에 마련되었다. 인텍스 머저(Index Merger)는 이러한 모든 데이터를 프로덕트조인(ProductJoin)으로 병합하는 스파크 잡(spark job) 이고 프로덕트조인(ProductJoin)은 상품에 대한 모든 것을 갖춘 프로토버프(protobuf) 구조였다. 그 이후 병합된 데이터는 에이치 베이스(Hbase)에 저장되었다. 다음 단계는 또 다른 스파크 잡인 인덱스 빌더(Index Builder)가 에이치 베이스에서 프로덕트조인을 소비하여 검색 인덱스를 생성하고 이를 분산 스토리지에 저장했다. 온라인 서빙 클러스터는 분산 스토리지에서 인덱스를 직접 다운로드하여 서빙하는 것이다. 인덱스는 한 번만 구축하면 모든 복제본에서 사용할 수 있다.
또한 쿼리 이해 서비스(Query Understanding Service)를 보다 효과적으로 지원하기 위해 쿼리 데이터에 대한 유사한 파이프라인도 구축했다.
인덱싱 플랫폼0.1 및 인덱싱 플랫폼1.0의 비교

단계3: 인덱싱 플랫폼2.0
인덱싱 플랫폼 1.0은 이미 성능과 확장성 이슈를 해결한 성공적인 플랫폼이었지만, 여전히 랭킹 개발자의 작업량 감소와 랭킹 시그널 구축에 대한 생산성 향상이라는 인덱싱 플랫폼의 또 다른 과제를 안고 있었다. 인덱싱 플랫폼 1.0은 개발자의 신속한 시그널 구축에 전혀 기여하지 못했다. 초보 랭킹 개발자가 신규 시그널을 만들고 실험을 구성하는데 몇 주가 소요되기도 했다. 데이터 소스를 찾고, 데이터 파이프 라인을 처리하고 워크 플로우 일정을 관리하는 데 막대한 시간을 쏟아 부어야 했기 때문이다.
인덱싱 플랫폼 2.0은 모든 랭킹 개발자가 데이터 소스, 데이터 파이프 라인 및 워크 플로우 일정 관리에 대한 걱정없이 오롯이 시그널의 로직에 집중할 수 있도록 해주는 인덱싱 버스(Indexing Bus)이다.

인덱싱 플랫폼2.0의 주요 변경 사항은 인덱싱 플랫폼1.0이 외부 하이브 테이블에서 시그널을 병합하는 것과 달리, 대부분의 시그널이 플랫폼 내부에서 생성된다는 것이다. 인덱싱 플랫폼2.0에서는 모든 원본 데이터가 그라운드 트루스 머저(Ground Truth Merger)에 의해 병합되어, 세션 롱 파서( Session Long Parser)로 모든 고객 행동을 파싱하고 머지한다. 이 둘은 모두 확장이 용이한 스파크 잡이다. 또한 프로젝트 조이너(ProductJoiner) 및 쿼리조이너(QueryJoiner)는 원본 데이터 및 세션 로그를 기반으로 모든 시그널을 파생시키는 임무를 수행한다.
이 프레임워크의 백미는 프로덕트조인(ProductJoin)과 쿼리조인(QueryJoin) 사이에 서클이 있다는 것이다. 이를 통해 단순한 시그널을 강력한 시그널로 진화시킬 수 있다. 예를 들어, 가격은 프로덕트 조인의 원본 데이터이다. 쿼리조인을 구축할 때 모든 프로덕트 조인의 가격 정보를 사용하여 쿼리 가격 분포를 구축한 다음, 상품 가격과 쿼리 가격 분포를 바탕으로 상품을 부스트(boosting)/디모트(demote)하는 시그널을 만들 수 있다. 이를 통해, 단순한 가격은 랭킹에서 강력한 시그널이 된다.
쿼리조인(QueryJoin)을 예로 들어 보면, 쿼리조인을 생성하는 프로세스는 다음과 같다.
원본 데이터 및 파싱된 세션 로그를 포함한 모든 소스 데이터를 로드한다.
노출, 클릭, 구매와 같은 기본적으로 집계된 원시 고객 행동 데이터를 쿼리 수준 및 상품 쿼리 수준으로 생성한다.
모든 시그널 프로세서를 실행하여 시그널을 생성한다.
모든 시그널을 갖춘 쿼리조인(QueryJoin)을 에이치베이스(Hbase)에 저장한다.
각 프로세서의 워크 플로우는 다음과 같다.

효율성 관점에서 보면, 과거에는 신규 시그널을 구축하기 위해, 원시 로그 파싱부터 시그널에 이르기까지 전체 파이프 라인을 구축해야 했다. 이를 위해 많은 하이브 쿼리/ 스파크 잡이 필요했고, 때문에 신규 시그널 생성에는 대개 몇 시간이 소요되었다. 뿐만 아니라, 우리는 대략 70 여 개의 파이프 라인을 보유하고 있어 유지보수는 거의 재앙에 가까울 정도이며, 리소스 낭비도 심하다. 하지만 인덱싱 플랫폼 2.0에서는 이제 로그를 파싱하고 원시 시그널을 생성하는 작업은 플랫폼에서 통합 제공되며, 신규 시그널을 추가하는 작업은 단지 Class를 구현하고 새로운 플랫폼에서 거의 무료인 데이터를 처리하는 몇몇 로직만 추가하면 된다.
인덱싱 버스 사용 전후 효율 비교

인덱싱 플랫폼 2.0의 강점
랭킹 가발자는 몇 시간 내에 신규 랭킹 시그널을 구축할 수 있으므로, 시그널 로직과 공식에 집중할 수 있다.
막대한 클러스터 자원을 절약할 수 있으며, 인덱싱 플랫폼 2.0에서 거의 무료로 신규 시그널을 추가할 수 있다.
시그널 품질을 보장하기 위해 유닛 테스트 / 통합 테스트를 제공한다.
미래 비전
이것은 변천사의 끝이 아니다. 이는 단지 시작일 뿐이다! 플랫폼 발전의 첫 걸음으로 상품과 쿼리 간의 관계를 구축했다. 향후, 우리는 추천, 광고 등 기타 비즈니스에 긍정적 영향을 줄 수 있는 고객, 상품, 쿼리, 카테고리, 브랜드 등 에서도 유사한 상호 관계를 구축할 예정이다. 궁국적으로, 인덱싱 플랫폼은 결국 쿠팡 비즈니스의 핵심이 될 것이다.
저자 : Winter Wang
쿠팡에서 현재 다양한 포지션을 채용하고 있습니다. 자세한 공고는 이 사이트에서 확인하실 수 있습니다.
 가입하기
가입하기