안녕하세요, 온라인 코딩 스쿨 코드잇입니다.
요즘 핫한 데이터 사이언스....!!
데이터 사이언스를 시작하기 위해서는 복잡한 프로그램 설치가 필요한데요, 오늘은 별도 프로그램 설치 없이 데이터 사이언스를 시작할 수 있는 방법을 소개해드릴게요.
누가 뭐래도, 프로그래밍에서 가장 어려운 부분은 설치입니다. 시작도 하기 전에 가장 어려운 걸 시키죠. 데이터 사이언스도 마찬가지인데요. 쥬피터 노트북, Numpy, Pandas, Matplotlib, Seaborn, BeautifulSoup 등등 설치해야할 게 산더미입니다.
그래서 정작 눈앞에 코드가 있는데도, 실행해보질 못하는데요. 설치 없이 데이터 사이언스 코드를 실행할 수 있는 방법이 있습니다.
바로 구글 Colaboratory! (일명 코랩, Colab) 구글 아이디만 있으면 됩니다.

▶쥬피터 노트북 생성하기
구글 로그인을 하고,
http://colab.research.google.com 여기로 접속하세요.
그럼 아래와 같은 화면이 나타날텐데요,

우측 아래에서 'NEW PYTHON 3 NOTEBOOK' 혹은 한글로 '새 PYTHON 3 노트'를 클릭하면 됩니다.
혹은 구글 드라이브에서 New > More 에 들어가서, Google Colaboratory를 선택해도 파일이 생성됩니다.

그러면 구글에서 제공하는 쥬피터 노트북의 온라인 환경이 나타납니다!

이제 코드를 실행할 준비가 끝났습니다.
▶쥬피터 노트북 둘러보기
이제 별도의 설치 없이, 바로 코드 실행이 가능합니다.
쥬피터 노트북에는 두 종류의 셀이 있는데요. 코드 셀과 텍스트 셀입니다.
코드 셀에서는 코드를 입력하거나 실행할 수 있고, 텍스트 셀에는 텍스트를 입력하거나 마크다운을 적용할 수 있습니다.
기본적으로 생성되는 셀이 바로 코드 셀입니다.

이 코드 셀에 코드를 입력할 수 있고, 컨트롤 + 엔터를 누르면 그 코드가 실행됩니다.
코드 셀을 더 만들고 싶다면, 좌측 상단에 '+Code' 버튼을 누르시면 됩니다.
▶쥬피터 노트북에서 코딩하기
코드를 직접 실행해 볼까요?
그냥 import pandas as pd 라고 하면, 구글이 미리 설치해둔 pandas 라이브러리가 pd라는 이름으로 불러와 집니다.
pandas의 read_csv() 메소드를 사용해서, 서울시 지하철 승하차 데이터를 읽어와 봅시다.
아래처럼 코드를 입력하고 실행해 보면,
import pandas as pd
df = pd.read_csv('https://www.dropbox.com/s/f9qdgwbozhk7yh8/subway.csv?dl=1')
df.head()
head() 메소드는 첫 5개의 데이터 결과를 보여 줍니다.
결과가 잘 나오는군요.
seaborn 같은 라이브러리도 별도의 설치 없이, 바로 사용할 수 있습니다.
import seaborn as sns 라고만 적어 주면, sns 라는 이름으로 seaborn을 사용할 수 있습니다.
import pandas as pd
import seaborn as sns
df = pd.read_csv('https://www.dropbox.com/s/f9qdgwbozhk7yh8/subway.csv?dl=1')
sns.jointplot(data=df, x='in', y='out')
seaborn은 데이터를 그래프로 만들어 주는 시각화 라이브러리인데요. 특히 데이터에서 인사이트를 발견할 수 있을만한 그래프가 많습니다.
seaborn의 다양한 그래프를 보시려면, 여기를 참고해 보세요. https://seaborn.pydata.org/examples/index.html
▶내 파일 업로드하기
내 컴퓨터의 파일도 업로드해서 사용할 수 있는데요.
google.colab이라는 라이브러리에 이 기능이 포함되어 있습니다.
일회성으로 쓸 파일은, files.upload() 를 통해 바로 업로드하면 됩니다.
from google.colab import files uploaded = files.upload()

'Choose Files'를 클릭해서 파일을 선택하면 업로드가 완료됩니다.

!ls 로 파일을 확인할 수 있습니다. (!ls 는 쥬피터 노트북에서 파일을 보는 매직 커맨드입니다.)
!ls

우리가 업로드한 subway.csv 파일이 보이죠?
이제 이 데이터를 사용해 볼까요? 아까와 같은 방식으로 read_csv() 메소드를 활용하면 됩니다.
import pandas as pd
df = pd.read_csv('subway.csv')
df.head()
이렇게 업로드한 파일은 일정 시간이 지나면 사라지는데요.
이후에 여러 번 쓸 파일이라면, 구글 드라이브에 업로드한 후 연동하면 됩니다.
from google.colab import drive
drive.mount('/content/drive')인증 과정이 필요한데, 생성되는 링크를 눌러서 인증 코드를 붙여넣으면 됩니다.
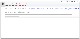
인증이 완료되면 이렇게 나옵니다.

이제 내 구글 드라이브의 파일을 가져와서 사용할 수 있습니다.
구글 드라이브의 파일들은 '/content/drive/My Drive' 이 경로에 들어가게 되는데요.
!ls '/content/drive/My Drive'
이렇게 하면 내 드라이브에 있는 파일만 볼 수 있습니다.
이 경로를 사용해서 파일을 가져와 봅시다. read_csv() 메소드를 사용하면 되겠죠?
저는 제 구글 드라이브의 dataset 폴더 안에 subway.csv 파일을 넣어 두었습니다.
import pandas as pd
df = pd.read_csv('/content/drive/My Drive/dataset/subway.csv')
df.head()
동일하게 결과가 잘 나오네요.
구글 Colab을 활용해서, 데이터 사이언스 코드를 실행시키는 법을 배워 봤습니다.
그런데, 쥬피터 노트북에 어떤 코드를 써야할지 모르겠다면?
쥬피터 노트북의 사용 방법과 Numpy, Pandas 사용법 및 데이터 분석 기법까지 좀 더 자세한 데이터 사이언스 강의가 듣고 싶다면, 코드잇에서 3일 무료로 체험해보세요!

 가입하기
가입하기





