JANDI 검색엔진 도입기
 토스랩(Toss Lab)
/ 조회수 : 2336
토스랩(Toss Lab)
/ 조회수 : 2336
토스랩(Toss Lab)
/ 조회수 : 2336
이번 포스트에서는 JANDI가 검색엔진을 도입하게 된 배경과 어떤 작업을 했는지 공유하려고 합니다
JANDI는 사용자가 입력한 메시지를 검색하고 사용자가 올린 파일의 파일명/파일 타입을 검색하는 메시지/파일 검색 기능을 제공하고 있습니다. 데이터 저장소로 MongoDB를 사용하고 있는데 검색되는 필드에 인덱스를 걸고 정규 표현식을 이용하여 DB Like 검색(“DB는 검색을 좋아한다”아니에요;;)을 하고 있습니다.
초기에는 데이터가 아담했는데, 서비스가 커감에 따라 사용자 증가하면서 생성되는 데이터도 많아졌습니다. 올 초에 데이터가 많아지면서 검색이 DB에 부하를 주고, JANDI 서비스에도 영향을 주게 되었습니다. 그래서 JANDI 서비스용 MongoDB와 검색 전용 MongoDB를 분리했는데 이는 임시방편이었고 언젠가는 꼭 검색엔진을 도입하자며 마무리를 지었습니다.
시간은 흘러 흘러 4월이 되었습니다. 당시 메시지 증가량을 봤을 때 올해 안에 검색엔진을 사용하지 않으면 서비스에 문제가 될 거라고 판단이 되어 도입을 진행하게 되었습니다.
검색엔진 도입의 목표는 다음과 같았습니다.
검색엔진 후보로는 Solr, ElasticSearch, CloudSearch, ElasticSearch Service 가 있었는데 Solr를 선택했습니다.
왜냐하면
현재 JANDI는 MongoDB를 데이터 저장소로 사용하고 있습니다. MongoDB의 데이터를 색인하기 위해 데이터를 검색엔진으로 가져와야 하는데 Solr에서는 DataImportHandler 기능을 제공하고 있습니다. 기본 DataImportHandler로 RDB 데이터는 가져올 수 있지만 이 외 MongoDB나 Cassandra 같은 NoSQL의 데이터를 가져오기 위해서는 따로 구현이 필요합니다. 구글신에게 물어봐서 SolrMongoImporter 프로젝트를 찾았는데 문제가 있었습니다. mongo-java-driver 버전이 낮아서(2.11.1) 현재 JANDI에서 서비스 되고 있는 MongoDB(3.0.x)의 데이터를 가져올 수 없었습니다.

url: Reference compatibility MongoDB Java
2.11.1에서 3.2.2로 버전을 올리고 변경된 api를 적용하는 작업, 빌드 툴을 ant에서 maven으로 변경하는 작업을 하였습니다. 마음의 여유가 된다면 P/R을 할 계획입니다.
여담으로 DataImportHandler 작업과 함께 검색 schema 정하는 작업을 했는데 sub-document 형식이 필요하게 되었습니다. Solr 5.3부터 nested object를 지원한다는 article을 보았는데, nested object 지원 얘기를 보니 Solr도 text search 뿐 아니라 log analysis 기능에 관심을 가지는건 아닐까 조심스레 생각해봤습니다. (역시나… 이미 banana, silk 같은 프로젝트가 있습니다. Large Scale Log Analytics with Solr 에 관련된 이야기를 합니다.)
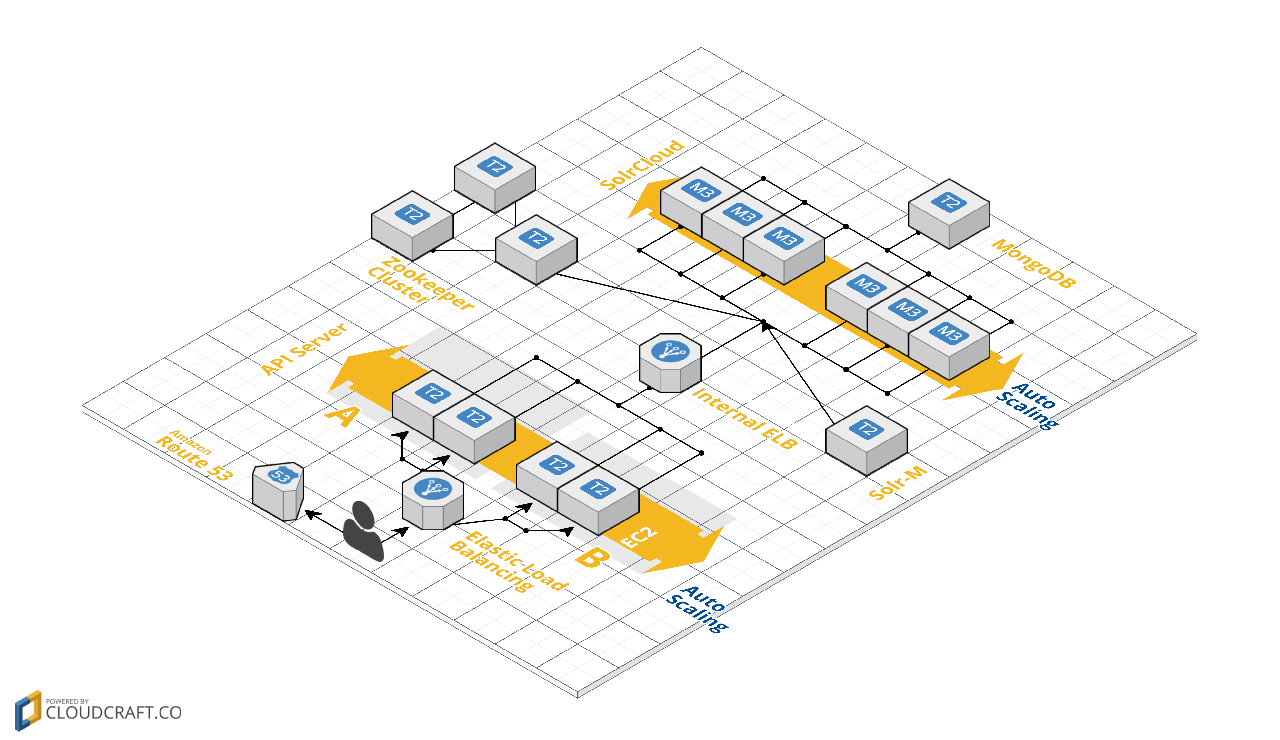
대량의 데이터를 처리하기 위해 한 개 이상의 node로 구성된 데이터 베이스에 문서를 나누어 저장하는 것을 sharding이라고 합니다. SolrCloud는 shard 생성/삭제/분리할 수 있는 API가 있고, 문서를 어떻게 나눌지 정할 수 있습니다. 어떻게 나눌지는 shard 생성 시 router.name queryString에 개발한 router 이름을 적어주면 됩니다. 그렇지않으면 Solr에서 murmur Hash 기반으로 문서를 나누는 compositeId router를 사용합니다. JANDI의 검색 기능은 Team 단위로 이루어지기 때문에 TeamId를 기준으로 문서를 나누기로 하고, compositeId Router를 사용했습니다. 실제 서비스의 문서 데이터를 색인 돌려서 각 node에 저장되는 문서 개수나 메모리/디스크 사용량을 확인했는데 다행히도 큰 차이가 나지 않았습니다.
하나의 문서는 TeamId와 MessageId를 조합한 “TeamId + ! + MessageId” 값을 특정 field에 저장하고 해당 필드를 uniqueKey 지정했습니다. 간단한 수정으로 문서 분배가 되는점이 좋았고, 더 좋았던건 검색시 _route_ 를 이용해서 실제 문서가 존재하는 node에서만 검색을 한다는 점이 었습니다.


4년 전 제가 마지막으로 Solr를 사용했을 때는 사용자가 직접 shards queryString에 검색할 node를 넣어주어야 했습니다.
.../select?q=\*:\*&shards=localhost:8983/solr/core1,localhost:8984/solr/core1
Solr에 기본으로 있는 text_cjk analyzer를 사용하였습니다.
<!-- normalize width before bigram, as e.g. half-width dakuten combine --> <!-- for any non-CJK -->
text_cjk는 영어/숫자는 공백/특수기호 단위로 분리해주고 cjk는 bigram으로 분리해주는 analyzer 입니다. analyzer는 이슈 없이 완성될 거라 생각했지만 오산이었습니다. 텍스트가 들어오면 token을 만들어주는 StandardTokenizerFactory 에서 cjk와 영어/숫자가 붙어있을 때는 분리하지 못해 원하는 결과가 나오지 않았습니다. 또한 특수기호중에 ‘.’(dot), ‘_‘(underscore)가 있을 때에도 분리하지 못했습니다.
| name | text |
|---|---|
| Input | Topic검색개선_AB1021_AB제시CD.pdf |
| StandardTokenizerFactory | Topic검색개선_AB1021_AB제시CD.pdf |
| CJKWidthFilterFactory | Topic검색개선_AB1021_AB제시CD.pdf |
| LowerCaseFilterFactory | topic검색개선_ab1021_ab제시cd.pdf |
| CJKBigramFilterFactory | topic검색개선_ab1021_ab제시cd.pdf |
| 원하는 결과 | topic 검색개선 ab 1021 ab 제시 cd pdf |
그래서 색인/검색 전에 붙어있는 cjk와 영어/숫자사이에 공백을 넣어주고 ‘.’와 ‘_‘를 공백으로 치환해주는 작업을 하였습니다. 색인은 Transform에서 처리하고 검색은 다음에 알아볼 QParserPlugin에서 처리했습니다.
| name | text |
|---|---|
| Input | Topic검색개선_AB1021_AB제시CD.pdf |
| Transform 단계 | Topic 검색개선 AB 1021 AB 제시 CD pdf |
| StandardTokenizerFactory | Topic 검색개선 AB 1021 AB 제시 CD pdf |
| CJKWidthFilterFactory | Topic 검색개선 AB 1021 AB 제시 CD pdf |
| LowerCaseFilterFactory | topic 검색개선 ab 1021 ab 제시 cd pdf |
| CJKBigramFilterFactory | topic 검색개선 ab 1021 ab 제시 cd pdf |
※ 추가 : 검색 결과를 보여줄때 어떤 키워드가 매칭되었는지 Highlight 해야했는데, 색인하기 전에 원본을 수정을 해서 Solr에서 제공하는 Highlight를 사용하지 못하게 됐습니다. 눈 앞의 문제만 바라보고 해결하기 급급했던 저를 다시금 반성하게 되었습니다.
앞에서도 언급하였지만, 색인뿐만 아니라 검색할 때도 검색어가 입력되면 검색하기 전에 붙어있는 cjk와 영어/숫자를 분리하고 ‘.’, ‘_‘를 공백으로 치환해주는 작업이 필요합니다. Solr에서 기본으로 사용하는 LuceneQueryParserPlugin 을 수정하였습니다.
@Override public Query parse() throws SyntaxError { // 수정한 코드 String qstr = splitType(getString()); if (qstr == null || qstr.length() == 0) return null;
String defaultField = getParam(CommonParams.DF); if (defaultField == null) { defaultField = getReq().getSchema().getDefaultSearchFieldName(); } lparser = new SolrQueryParser(this, defaultField);
lparser.setDefaultOperator (QueryParsing.getQueryParserDefaultOperator(getReq().getSchema(), getParam(QueryParsing.OP)));
return lparser.parse(qstr); }
MongoImporter에서도 얘기했지만 Solr에서는 DB 데이터를 가져오는 DataImportHandler 기능을 제공 하고 있습니다. DataImportHandler Commands를 보면 총 5개의 명령을 제공하고 있는데, 그중 색인을 실행하는 명령은 full-import와 delta-import입니다. full-import 명령은 DB의 모든 데이터를 색인 하는 것을 말합니다. 색인 시작할 때의 시간을 conf/dataimport.properties에 저장하고 이때 저장한 시간은 delta-import 할때 사용됩니다. 전체 색인한다고 말합니다. delta-import 명령은 특정 시간 이후로 생성/삭제된 데이터를 색인 하는 것을 말합니다. 특정 시간이란 full-import 시작한 시간, delta-import가 최근 종료한 시간을 말합니다. full-import와는 다르게 delta-import가 종료된 시간을 conf/dataimport.properties에 저장합니다. 증분 색인 혹은 동적 색인이라고 하는데 여기서는 증분 색인이라고 얘기하겠습니다. 두 명령을 이용하여 JANDI의 메시지/파일을 색인 하기 위한 삽질 경험을 적었습니다.
full-import는 현재 active인 데이터를 가져올 수 있도록 query attribute에 mongo query를 작성하고, delta-import 는 특정 시간 이후에 생성된 데이터를 가져올 수 있도록 deltaQuery attribute에 mongo query를 작성합니다. 또한 deltaQuery로 가져온 id의 문서를 가져올 수 있도록 deltaImportQuery attribute에 mongo query를 작성하고, 특정 시간 이후에 삭제된 데이터를 가져올 수 있도록 deletedPkQuery 에도 mongo query를 작성합니다.
<!-- data-config.xml -->
<?xml version="1.0" encoding="UTF-8" ?>
정상적으로 동작은 했지만, 색인 속도가 실제 서비스에 적용하기 힘들 정도였습니다. 실행되는 mongo query를 확인했는데 다음과 같이 동작하였습니다.

특정 시간 이후에 생성된 데이터를 색인하기 위해 약 (새로 생성된 문서개수 + 1) 번의 mongo query가 실행되었습니다. (batch size와 문서 갯수에 따라 늘어날 수도 있습니다.) 메신저 서비스 특성상 각각의 문서 크기는 작지만 증가량이 빠르므로 위 방식으로는 운영 할 수 없었습니다. 그래서 delta-import using full-import 를 참고해서 두 번째 삽질을 시작 하였습니다.
full-imoprt 명령을 실행할 때 clean=false queryString을 추가하고 data-config.xml query attribute를 수정하는 방법으로 증분 색인 하도록 수정했습니다. 특정 시간 이후 생성된 문서를 가져오는 attribute인 deltaQuery와 deltaImportQuery 는 필요가 없어 지웠습니다.
<!-- data-config.xml -->
<?xml version="1.0" encoding="UTF-8" ?>
<!-- if query="" then it imports everything -->
전체 색인은 /dataimport?command=full-import&clean=true 로 실행하고, 증분 색인은 /dataimport?command=full-import&clean=false(생성된 문서)와 …/dataimport?command=delta-import&commit=true(삭제된 문서)로 실행하도록 했습니다.
정상적인 것 같았지만, 문제가 있었습니다.
full-import, delta-import 명령을 실행하면 conf/dataimport.properties 파일에 전체 색인이 실행한 시작 시각 혹은 증분 색인이 최근 종료한 시간이 “last_index_time” key로 저장됩니다. 첫 번째 삽질에서 증분 색인시 delta-import 명령 한 번으로 생성된 문서와 삭제된 문서를 처리했지만, full-import와 delta-import 두개의 명령으로 증분 색인이 동작하면서 생성된 문서를 처리할 때도 last_index_time이 갱신되고 삭제된 문서를 처리할 때도 last_index_time이 갱신되었습니다.
예를 들면
증분색인 동작이 1분마다 삭제된 문서를 처리하고, 5분마다 생성된 문서를 처리 한다고 가정해보겠습니다. 3시 13분 14초에 delta-import가 완료되어 last_index_time에 저장되고, 다음 delta-import가 실행되기 전 3시 13분 50초에 full-import가 완료되어 last_index_time이 갱신되었다면, 3시 13분 14초부터 3시 13분 50초 사이에 삭제된 문서는 처리를 못 하는 경우가 발생합니다.
Solr에서 dataimport.properties에 기록하는 부분을 수정하는 방법과 전체/증분 색인을 동작시키는 Solr 외부에서 특정 색인 시간을 관리하는 방법이 있었는데 Solr를 수정하는 건 생각보다 큰 작업이라 판단되어 외부에서 관리하는 방법으로 세 번째 삽질을 시작하였습니다.
전체/증분 색인을 주기적으로 동작 시키는 곳에서 full-import&clean=false(생성된 문서) 처리할 때 필요한 마지막으로 색인 된 문서 id와 delta-import(삭제된 문서) 처리할 때 필요한 마지막으로 색인 된 시간을 관리하도록 개발하였습니다. 증분 색인 시 full-import&clean=false를 실행하기 전에 현재 색인 된 마지막 id 조회 후 해당 id보다 큰 데이터를 처리하도록 하였고, delta-import를 마지막으로 마친 시간을 따로 저장하다가 delta-import 실행 시 해당 시간을 전달하는 방법으로 수정하였습니다.
<!-- data-config.xml -->
<?xml version="1.0" encoding="UTF-8" ?>
튜닝의 끝은 순정이라는 말이 있는데 IT 기술은 예외인 것 같습니다. 현재는 Solr의 기본 기능만으로 구성했지만, 고객에게 더 나은 서비스를 제공할 수 있는 시작점으로 생각하고, JANDI 서비스에 맞게 끊임없이 발전해나가겠습니다.
감사합니다.

참고
#토스랩 #잔디 #JANDI #개발자 #개발팀 #개발후기 #인사이트
관련 스택

 가입하기
가입하기