이 포스팅은 Bidirectional LSTM에 대한 기본 개념을 소개하고, tensorflow와 MNIST 데이터를 이용하여 구현해 봅니다.
앞에서 RNN 과 LSTM 모델에 대해 소개했습니다.
기본적인 LSTM 모델은 이전 시간의 step들이 다음 step에 영향을 줄 것이라는 가정을 했습니다.
하지만 이후의 step 또한 앞의 step 에 영향을 줄 수 있다면 이 모델을 어떻게 적용시킬 수 있을까요?
이후의 step 의 영향도 반영한 모델이 Bidirectional LSTM 모델입니다.

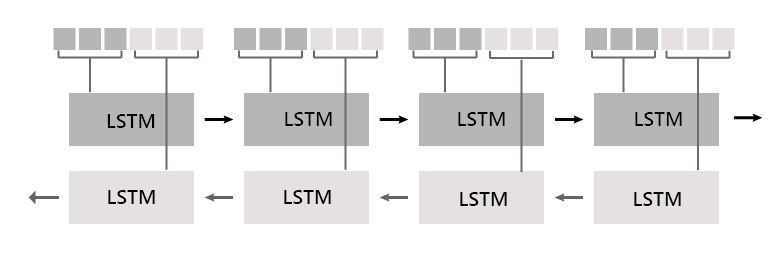
위의 그림과 같이 BLSTM 은 두 개의 LSTM 모델을 Concatenate 하여 사용합니다.

Time step 이 1부터 t 까지 있다고 가정할 때 forward lstm model 에서는 input 을 Time step 이 1 일때부터 t 까지 순차적으로 주고 학습합니다.
반대로 backward lstm model 에서 input 을 T = t 일때부터 1까지 거꾸로 input 주고 학습을 하게 됩니다.
time step 마다 두 모델에서 나온 2개의hidden vector은 학습된 가중치를 통해 하나의 hidden vector로 만들어지게 됩니다.
전체 코드는 Github page 를 참고해주세요.
MNIST image 를 input 으로 넣었을 때 이 image 가 0 에서 9 중에 어떤 숫자인지 맞추는 BLSTM 모델을 만들어 보고자 합니다.
MNIST 는 0 - 9 의 숫자 image data 이며 각 데이터는 28 x 28 의 matrix (data 는 28 x 28 길이의 array) 로 이루어져 있습니다.
앞에서 봤듯이 LSTM 은 sequence 형태를 요구합니다.
그래서 데이터 하나를 한 번에 넣는 것이 아니라 각 데이터의 matrix 를 row 만큼, 즉 28번의 time step 으로 나누어 넣어주게 됩니다.
그래서 input_sequence 를 28 길이로 설정합니다.
learning_rate = 0.001
training_epochs = 10 # 전체 데이터를 몇번 반복하여 학습 시킬 것인가
batch_size = 256 # 한 번에 받을 데이터 개수
# model
# 입력되는 이미지 사이즈 28*28
input_size = 28 # input size(=input dimension)는 셀에 입력되는 리스트 길이
input_steps = 28 # input step(=sequence length)은 입력되는 리스트를 몇개의 time-step에 나누어 담을 것인가?
n_hidden = 128
n_classes = 10 # classification label 개수
X = tf.placeholder(tf.float32,[None, input_steps, input_size])
Y = tf.placeholder(tf.float32,[None, n_classes])
W = tf.Variable(tf.random_normal([n_hidden * 2, n_classes]))
b = tf.Variable(tf.random_normal([n_classes]))
X 는 28 x 28 의 matrix 로 이루어진 데이터를 받고 Y 는 실제 class (0 - 9) 를 의미하는 length 10 의 vector 를 받습니다.
그리고 각 forward lstm 모델과 backward lstm 모델에서 들어오는 weight 값을 받을 변수를 설정합니다.
DropoutWrapper 는 모델에서 input 으로 주어진 data 에 대한 Overfitting 이 발생하지 않도록 만들어주는 모델입니다.
각 state 를 랜덤하게 비활성화시켜서 데이터를 더 random 하게 만들어줍니다. keep_prob 변수를 통해서 dropoutWrapper 의 확률값을 조정합니다.
keep_prob = tf.placeholder(tf.float32)
forward lstm 과 backward lstm 에서 사용할 cell을 생성합니다
# lstm cell 생성
lstm_fw_cell = tf.nn.rnn_cell.LSTMCell(num_units = n_hidden, state_is_tuple = True)
lstm_fw_cell = tf.nn.rnn_cell.DropoutWrapper(lstm_fw_cell, output_keep_prob=keep_prob)
lstm_bw_cell = tf.nn.rnn_cell.LSTMCell(num_units = n_hidden, state_is_tuple = True)
lstm_bw_cell = tf.nn.rnn_cell.DropoutWrapper(lstm_bw_cell, output_keep_prob=keep_prob)
학습할 모델을 생성합니다
outputs,_ = tf.nn.bidirectional_dynamic_rnn(lstm_fw_cell,lstm_bw_cell, X, dtype = tf.float32)
기존의 lstm 과 달리 output 이 2개의 LSTMStateTuple 로 이루어져 있습니다.
각 output 에 가중치를 더해서 하나의 output 으로 만들어주는 과정이 필요합니다.
여기서 가장 헷갈리는 부분이 transpose 입니다. 왜 output 에 대해서 transpose를 하는 것인지 의문이 들 수 있습니다.
tf.nn.bidirectional_dynamic_rnn 문서를 보시면 output 의 default 는 [batch_size,max_time,depth] 라고 나와있습니다.
각각 mini batch 의 크기 그리고 time step, hidden state 의 depth 를 의미합니다.
우리는 각 데이터마다 마지막 time step 의 결과값을 output 으로 선택해야 합니다.
그래야지 전체 step 이 반영된 output 을 얻을 수 있습니다.
outputs_fw = tf.transpose(outputs[0], [1,0,2])
outputs_bw = tf.transpose(outputs[1], [1,0,2])
pred = tf.matmul(outputs_fw[-1],w_fw) +tf.matmul(outputs_bw[-1],w_bw) + biases
matmul operation 연산 속도를 위해서 다음과 같이 하나의 output 으로 먼저 합치고 전체에 대한 가중치를 주는 것이 더 좋은 방법입니다.
outputs_concat = tf.concat([outputs_fw[-1], outputs_bw[-1]], axis=1)
pred = tf.matmul(outputs_concat,W) + b
이하 코드는 이전의 tutorial 과 동일합니다.
관련 스택

 가입하기
가입하기