이 포스팅은 LSTM에 대한 기본 개념을 소개하고, tensorflow와 MNIST 데이터를 이용하여 구현해봅니다.
LSTM(Long Short Term Memory)은 RNN(Recurrent Neural Networks)의 일종으로서, 시계열 데이터, 즉 sequential data를 분석하는 데 사용됩니다.
기존 RNN모델은 구조적으로 vanishing gradients라는 문제를 가지고 있습니다. RNN은 기본적으로 Neural network이기 때문에 chain rule을 적용하여 backpropagation을 수행하고, 예측값과 실제 결과값 사이의 오차를 줄여나가면서 각 시간 단계의 gradient를 조정합니다. 그런데, 노드와 노드(시간 단계) 사이의 길이가 길어지다보면, 상대적으로 이전의 정보가 희석됩니다. 이 문제는 시퀀스 상 멀리 떨어져 있는 요소, 즉 오래 전에 발생한 이벤트 사이의 연관성을 분석할 수 없도록 만듭니다.

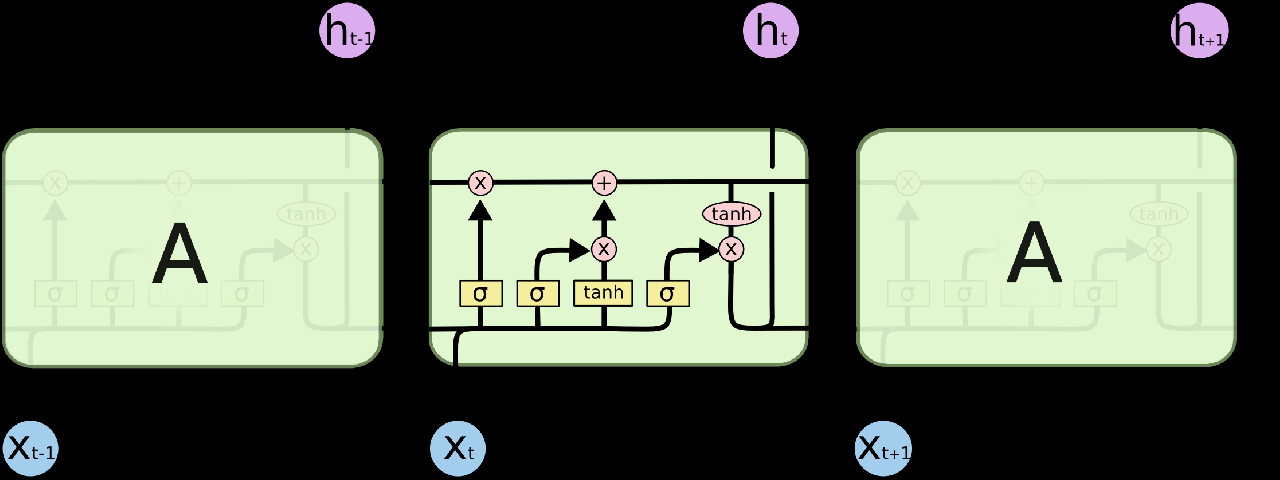
LSTM은 RNN의 문제를 셀상태(Cell state)와 여러 개의 게이트(gate)를 가진 셀이라는 유닛을 통해 해결합니다. 이 유닛은 시퀀스 상 멀리 있는 요소를 잘 기억할 수 있도록 합니다. 셀상태는 기존 신경망의 은닉층이라고 생각할 수 있습니다. 셀상태를 갱신하기 위해 기본적으로 3가지의 게이트가 필요합니다. Forget, input, output 게이트는 각각 다음과 같은 역할을 합니다.
Forget : 이전 단계의 셀 상태를 얼마나 기억할 지 결정합니다. 0(모두 잊음)과 1(모두 기억) 사이의 값을 가지게 됩니다. Input : 새로운 정보의 중요성에 따라 얼마나 반영할지 결정합니다. Output : 셀 상태로부터 중요도에 따라 얼마나 출력할지 결정합니다.
게이트는 가중치(weight)를 가진 은닉층으로 생각할 수 있습니다. 각 가중치는 sigmoid층에서 갱신되며 0과 1사이의 값을 가지고 있습니다. 이 값에 따라 입력되는 값을 조절하고, 오차에 의해 각 단계(time step)에서 갱신됩니다.
MNIST는 손으로 쓴 숫자 이미지 데이터입니다. 하나의 이미지는 가로 28개, 세로 28개, 총 784개의 값으로 이루어져 있습니다.
Many-to-One model는 여러 시퀀스를 넣었을 때 나오는 최종 결과물만을 이용하는 모델입니다. 이를 이용하여 784개의 input으로 1개의 output값(A) 을 도출합니다. 이 A를 하나의 층에 통과시켜 10개의 숫자 label중 하나를 할당합니다.

784개의 입력값을 사이즈가 28인 벡터가 28번 이어지는 시퀀스(time step)로 보고, input의 크기를 28, 시퀀스 길이를 28로 각각 설정합니다. 28개의 input은 C라고 표현되어 있는 LSTM 셀로 순차적으로 들어가게 됩니다.

output의 크기는 셀의 크기와 같으며, 64로 설정하였습니다. 셀크기가 너무 작으면 많은 정보를 담지 못하기 때문에 적당히 큰 값으로 설정합니다. 전체 output은 64개의 값을 가지고 있는 벡터 28개의 집합이 되고, 마지막 벡터만 사용합니다.

1층의 fully connected layer를 이용하여 64차원 벡터를 10차원으로 줄이고 softmax를 이용하여 0부터 9까지 중 하나의 값을 예측합니다.

LSTM으로부터 나온 예측값을 실제갑과 비교하여 cost를 개산합니다. cost function은 cross-entropy를 이용합니다. AdamOptimizer를 이용하여 cost를 최소화하는 방향으로 모델을 최적화 시킵니다.
구현 시 어려웠던 점을 중심으로 서술하였습니다. 전체 코드는 여기를 참고해주세요.
batch_size = 128
batch_x, batch_y = mnist.train.next_batch(batch_size)
MNIST의 train data의 크기는 55,000개 입니다. 이는 (55000, 784) 크기의 데이터를 학습시켜야 한다는 것을 의미합니다. 이것을 한번에 학습시킨다는 것은 매우 어려운 일입니다. 전체 데이터를 메모리에 올리기 힘들뿐만 아니라, 너무 큰 data 한번에 학습시키면 가장 작은 cost값으로 수렴하기 힘들어진다는 문제가 있습니다. (너무 작아도 마찬가지입니다.) 그렇기 때문에 큰 덩어리를 일정크기의 작은 덩어리로 잘라서 모델에 넣어 학습시는데, 이 작은 덩어리의 크기를 batch size라고 합니다.
작은 덩어리로 짜르는 것이 중요한 이유는, 작은 덩어리 단위로 모델에 밀어넣고(propagation) 네트워크의 파라미터들을 조정(update)하기 때문입니다. batch size는 분석하려고 하는 데이터가 어떻게 구성되어있는지에 따라 결정되는 경우가 많습니다. 어떤 수준의 batch size가 좋다고 이야기하기 어렵고, 아주 크지 않은 값으로 설정합니다.
모델 구현 시 static RNN을 사용하였습니다. Static RNN에서는 unstack을 해주지 않으면 TypeError가 발생합니다.
unstack( value, num=none, axis=0, name=‘unstack’)
unstack은 R차원(rank)의 데이터를 R-1 차원으로 줄여주는 역할을 합니다. value로부터 axis 차원을 기준으로 num개로 자른다고도 할 수 있습니다. 이 예제로 예를 들어보겠습니다.
batch_x = batch_x.reshape((batch_size, input_steps, input_size))
x = tf.unstack(X, input_steps, axis=1)
outputs1, states1 = tf.nn.static_rnn(lstm_cell, x, dtype=tf.float32)
실제 학습이 진행되는 순서로 보자면, batch size만큼 불러온 인풋 데이터는 (128, 784)에서 (128, 28, 28) 형식의 3차원 벡터로 reshape해 줍니다. 그리고 다시 unstack을 통해 time step을 기준으로(axis=1) 28개의 텐서를 만듭니다. 다시말해, (128, 28, 28)이라는 3차원 형식의 벡터는 (128, 28)이라는 2차원 벡터 28개로 변환되어 모델에 입력되게 됩니다. 이런 변환이 필요한 이유는 28*28의 크기를 가진input들을 차례로 넣게 되면 처리속도가 제한적이기 때문입니다. unstack을 이용하면 하나의 batch 안에 있는 input을 한꺼번에 한줄씩 병렬적으로 처리할 수 있게 됩니다.

Dynamic RNN에서는 unstack을 해주는 과정이 필요 없습니다. Static과 Dynamic의 차이는 추후 포스팅에서 자세히 다루도록 하겠습니다.
참고한 다른 예제코드들은 서로 다른 스타일의 사이클로 학습시키고 있었습니다. 스타일은 크게 두가지로 나누어볼 수 있었습니다. 하나의 방법은 전체 학습 횟수를 정해놓고 while문을 통해 학습시키는 방법이었습니다. 다른 방법은 똑같은 데이터를 몇번 반복해서 학습시킬지 결정하는 것입니다. 이 반복 횟수를 epoch이라고 합니다. epoch의 사전적 의미는 ‘시대’ 또는 ‘세’이지만 예제 코드에서 만나는 epoch은 전체 데이터를 학습시키는 반복회수라고 이해하시면 되겠습니다. (이 두가지 방법은 스타일의 문제일 뿐입니다. 이것을 언급한 이유는 개인적으로 epoch을 처음 접했을 때 생소했기 때문입니다.
for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(mnist.train.num_examples/batch_size)
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, input_steps, input_size))
c, _ = sess.run([cost2, optimizer2], feed_dict={X:batch_x, Y:batch_y})
avg_cost += c/total_batch
위의 코드는 두번째 스타일이고, 각 epoch마다 cost값과 test data로 예측의 accuracy를 계산하여 출력하였습니다. 당연하게도 학습이 반복 될수록 cost는 감소하고 accuracy는 증가하였습니다.
기본적으로 도식을 통해 input size, time step, hidden_size에 대한 개념을 이해하는 것이 도움이 됩니다.
tensor의 shape을 이해하는 것이 중요하다고 생각합니다. input과 output의 형식(shape)을 머리속에 떠올릴 수 있다면 에러를 줄일 수 있고 해결하기도 수월합니다.
batch size의 의미, unstack을 하는 이유, epoch의 의미를 알아두면 좋겠습니다.
DEEPLEARNING4J 초보자를 위한 RNNs과 LSTM 가이드
Colah’s blog, Understanding LSTM Networks
김성훈, 모두의 딥러닝 lec 9-2. Vanishing gadient
관련 스택

 가입하기
가입하기