조회수 1782
AWS Rekognition + PHP를 이용한 이미지 분석 예제 (2/2)
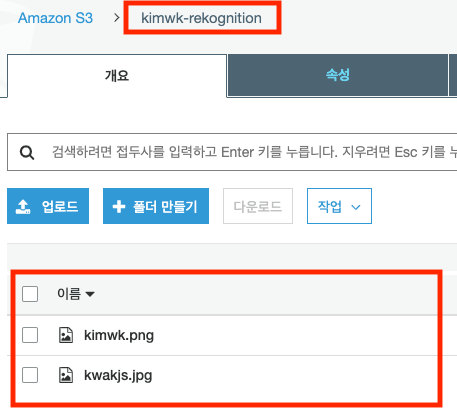
이전 글 보기: AWS Rekognition + PHP를 이용한 이미지 분석 예제 (1/2)Overview지난 글에서는 AWS Rekognition을 이용해 S3 Bucket에 업로드한 이미지로 이미지 분석 결과를 확인했습니다. 이번엔 더 나아가 Collection(얼굴 모음)을 생성해보고, 얼굴 검색을 해보겠습니다.1. Collection 만들기Collection은 AWS Rekognition의 기본 리소스입니다., 생성되는 각각의 컬렉션에는 고유의 Amazon 리소스 이름(ARN)이 있습니다. 컬렉션이 있어야 얼굴들을 저장할 수 있습니다. 저는 ‘BrandiLabs’라는 이름의 Collection을 생성했습니다.1-1. createRekognition 메소드를 이용해 손쉽게 Collection 을 생성합니다.# 클라이언트 생성 $sdk = new \\Aws\\Sdk($sharedConfig); $rekognitionClient = $sdk->createRekognition(); # 모음(Collection) 이름 설정 $collection = array('CollectionId' => 'BrandiLabs'); $response = $rekognitionClient->createCollection($collection); 1-2. Collection이 정상적으로 생성되었다면 아래와 같은 응답을 받습니다.[ { "StatusCode" : 200 "CollectionArn" : "aws:rekognition:region:account-id:collection/BrandiLabs" /*...*/ } ] 2. Collection에 얼굴 추가IndexFaces 작업을 사용해 이미지에서 얼굴을 감지하고 모음에 추가할 수 있습니다. (JPEG 또는 PNG) 모음에 추가할 이미지에 대해서는 몇 가지의 권장사항[1]이 있습니다.두 눈이 잘 보이는 얼굴 이미지를 사용합니다.머리띠, 마스크 등 얼굴을 가리는 아이템을 피합니다.밝고 선명한 이미지를 사용합니다.권장사항에 최적화된 사진은 S3 Bucket 에 업로드되어 있어야 합니다. 미리 ‘kimwk-rekognition’ 이라는 이름으로 버킷을 생성 후 제 사진과 곽정섭 과장님의 사진을 업로드해두었습니다.2-1. IndexFaces 메소드를 이용해 얼굴을 추가합니다. 예시에서는 제 얼굴과 곽 과장님의 얼굴을 인덱싱했습니다.$imageInfo = array(); $imageInfo['S3Object']['Bucket'] = 'kimwk-rekognition'; $imageInfo['S3Object']['Name'] = 'kwakjs.jpg'; $parameter = array(); $parameter['Image'] = $imageInfo; $parameter['CollectionId'] = 'BrandiLabs'; $parameter['ExternalImageId'] = 'kwakjs'; $parameter['MaxFaces'] = 1; $parameter['QualityFilter'] = 'AUTO'; $parameter['DetectionAttributes'] = array('ALL'); $response = $rekognitionClient->indexFaces($parameter); 각각의 요청 항목에 대한 상세 설명은 아래와 같습니다.Image : 인덱싱 처리할 사진의 정보입니다.CollectionId : 사진을 인덱싱할 CollectionId 입니다.ExternalImageId : 추후 인식할 이미지와 인덱싱된 이미지를 연결할 ID 입니다.MaxFaces : 인덱싱되는 최대 얼굴 수 입니다. 작은 얼굴(ex. 배경에 서 있는 사람들의 얼굴)은 인덱싱하지 않고 싶을 때 유용합니다.QualityFilter : 화질을 기반으로 얼굴을 필터링하는 옵션입니다. 기본적으로 인덱싱은 저화질로 감지된 얼굴을 필터링합니다. AUTO를 지정하면 이러한 기본 설정을 명시적으로 선택할 수 있습니다. (AUTO | NONE)DetectionAttributes : 반환되는 얼굴 정보를 다 가져올 것인지 아닌지에 대한 옵션입니다. ALL 로 하면 모든 얼굴 정보를 받을 수 있지만 작업을 완료하는데 시간이 더 걸립니다. (DEFAULT | ALL)2-2. Collection에 정상적으로 얼굴이 추가되었다면 아래와 같은 응답을 받습니다. 사진 속 인물의 성별, 감정, 추정 나이 등의 정보를 확인할 수 있습니다.[ { "Face":{ "FaceId":"face-id", "BoundingBox":{ "Width":0.28771552443504333, "Height":0.3611610233783722, "Left":0.39002931118011475, "Top":0.21431422233581543 }, "ImageId":"image-id", "ExternalImageId":"kimwk", "Confidence":99.99978637695312 }, "FaceDetail":{ "BoundingBox":{ "Width":0.28771552443504333, "Height":0.3611610233783722, "Left":0.39002931118011475, "Top":0.21431422233581543 }, "AgeRange":{ "Low":20, "High":38 }, "Smile":{ "Value":false, "Confidence":85.35209655761719 }, "Eyeglasses":{ "Value":false, "Confidence":99.99824523925781 }, "Sunglasses":{ "Value":false, "Confidence":99.99994659423828 }, "Gender":{ "Value":"Male", "Confidence":99.35176849365234 }, "Beard":{ "Value":false, "Confidence":94.80714416503906 }, "Mustache":{ "Value":false, "Confidence":99.92304229736328 }, "EyesOpen":{ "Value":true, "Confidence":99.64280700683594 }, "MouthOpen":{ "Value":false, "Confidence":99.4529037475586 }, "Emotions":[ { "Type":"HAPPY", "Confidence":2.123939275741577 }, { "Type":"ANGRY", "Confidence":6.1253342628479 }, { "Type":"DISGUSTED", "Confidence":19.37765121459961 }, { "Type":"SURPRISED", "Confidence":7.136983394622803 }, { "Type":"CONFUSED", "Confidence":30.74079132080078 }, { "Type":"SAD", "Confidence":9.113149642944336 }, { "Type":"CALM", "Confidence":25.382152557373047 } ], "Landmarks":[ { "Type":"eyeLeft", "X":0.45368772745132446, "Y":0.31557807326316833 }, … ], "Pose":{ "Roll":5.615509986877441, "Yaw":-5.510941982269287, "Pitch":-17.47319793701172 }, "Quality":{ "Brightness":93.13915252685547, "Sharpness":78.64350128173828 }, "Confidence":99.99978637695312 } } ] 3. 얼굴 검색드디어 얼굴 검색의 시간이 왔습니다. searchFacesByImage 메소드를 이용하면 지금까지 그래왔던 것처럼 쉽게 얼굴 검색을 할 수 있습니다. 저는 ‘kimwk2.jpg’ 라는 또 다른 제 얼굴 사진을 S3 Bucket에 업로드해뒀습니다. 얼굴 검색이 제대로 이루어졌다면 응답으로 제 ExternalImageId (kimwk) 가 내려올 것입니다. 한 번 해볼까요?3-1. searchFacesByImage 메소드를 이용해 얼굴 검색을 합니다.$imageInfo = array(); $imageInfo['S3Object']['Bucket'] = 'kimwk-rekognition'; $imageInfo['S3Object']['Name'] = 'kimwk2.jpg'; $parameter = array(); $parameter['CollectionId'] = 'BrandiLabs'; $parameter['Image'] = $imageInfo; $parameter['FaceMatchThreshold'] = 70; $parameter['MaxFaces'] = 1; $response = $rekognitionClient->searchFacesByImage($parameter); 3-2. 정상적으로 검색이 되었다면 아래와 같은 응답을 받습니다.[ { "Similarity":99.04029083251953, "Face":{ "FaceId":"FaceId", "BoundingBox":{ "Width":0.23038800060749054, "Height":0.2689349949359894, "Left":0.2399519979953766, "Top":0.08848369866609573 }, "ImageId":"ImageId", "ExternalImageId":"kimwk", "Confidence":100 } } ] SearchFacesByImage는 기본적으로 알고리즘이 80% 이상의 유사성을 감지하는 얼굴을 반환합니다. 유사성은 얼굴이 검색하는 얼굴과 얼마나 일치하는지를 나타냅니다. FaceMatchThreshold 값을 조정하면 어느 정도까지 유사해야 같은 얼굴이라고 허용할지를 정할 수 있습니다.Conclusion이미지 분석 알고리즘과 얼굴 검색 기능을 직접 구현하려 했다면 시간이 많이 걸렸겠지만 AWS 서비스를 이용하면 이미지 분석을 금방 할 수 있습니다. 이 기능을 잘 활용하면 미아 찾기나 범죄 예방과 같은 공공 안전 및 법 진행 시나리오에도 응용할 수도 있겠죠. 다음엔 보다 재밌는 주제로 찾아오겠습니다.참고[1] 얼굴 인식 입력 이미지에 대한 권장 사항[2] Amazon Rekonition 개발자 안내서[3] 모든 예제는 AmazonRekognition, AmazonS3에 대한 권한이 있어야 함글김우경 대리 | R&D 개발1팀kimwk@brandi.co.kr브랜디, 오직 예쁜 옷만