조회수 791
컴공생의 AI 스쿨 필기 노트 ④ 교차 검증과 정규화
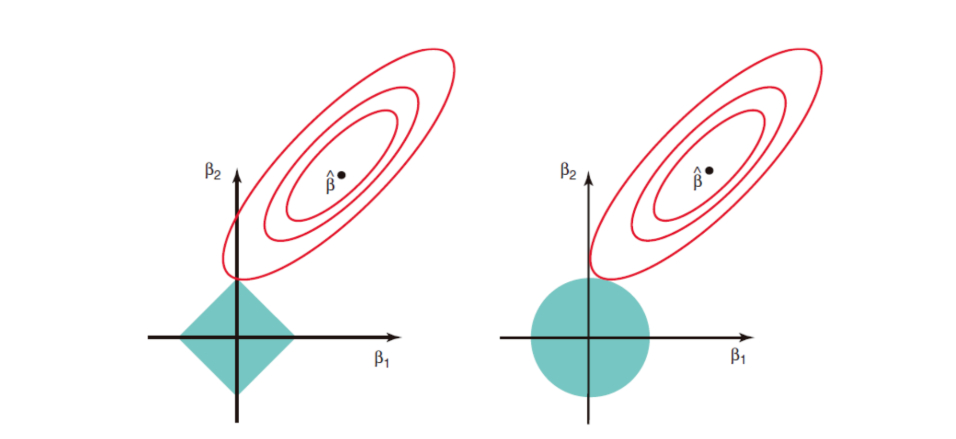
지금까지 Linear Regression, Logistic Regression 모델을 만들어보았는데요. 우리가 만든 모델이 과연 잘 만들어진 모델이라고 볼 수 있을까요? 이를 알기 위해서 이번 4주차 수업에서는 우리가 만든 모델의 적합성을 보다 객관적으로 평가하기 위한 방법으로 교차 검증(Cross Validation)과 정규화(Regularization)를 배웠어요. 차례대로 하나씩 알아볼까요?1. Cross Validation교차 검증은 새로운 데이터셋에 대해 반응하는 모델의 성능을 추정하는 방법이에요. 학습된 모델이 새로운 데이터를 받아들였을 때 얼마나 예측이나 분류를 잘 수행하는지 그 성능을 알기 위해서는 이에 대한 추정 방식이 필요해요. 먼저 Whole population(모집단)에서 Y와 f를 구하기 위해 Training Set(모집단에서 나온 데이터셋)에서 f와 똑같지 않지만 비슷한 모델 f^를 만들어요. 그리고 이 모델을 모집단에서 나온 또 다른 데이터 셋인 Test Set을 이용하여 확인해요. 하지만 일반적으로 Test Set이 별도로 존재하는 경우가 많지 않기 때문에 Training Set을 2개의 데이터셋으로 나눠요. 이 Training Set에서 Training Set과 Test Set을 어떻게 나누느냐에 따라 모델의 성능이 달라질 수 있어요. 이런 테스트 방법을 교차 검증(Cross validation)이라고 해요.이번 시간에는 교차 검증 방법으로 LOOCV(Leave-One-Out Cross Validation)와 K-Fold Cross Validation을 알아봤어요. LOOCV(Leave-One-Out Cross Validation)LOOCV는 n 개의 데이터 샘플에서 한 개의 데이터 샘플을 test set으로 하고, 1개를 뺀 나머지 n-1 개를 training set으로 두고 모델을 검증하는 방식이에요.K-Fold Cross ValidationK-Fold CV는 n 개의 데이터를 랜덤하게 섞어 균등하게 k개의 그룹으로 나눠요. 한 개의 그룹이 test set이고 나머지 k-1개의 그룹들이 training set이 되어 k번을 반복하게 돼요. LOOCV도 n-fold CV로 볼 수 있어요!코드로 나타내기Step1. 데이터 생성 & train set과 test set 단순 분리# model selection modulefrom sklearn.model_selection import train_test_splitfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis# read datadf = pd.read_csv('data/data01_iris.csv')data = df.iloc[:,:-1].as_matrix()target = df['Species'].factorize()[0]LOOCV와 K-Fold CV에 사용할 데이터를 구하는 코드에요. data 파일 안의 data01.csv 파일을 읽어서 데이터 프레임 형태로 가져와요.df(데이터 프레임) 안에는 이와 같은 105개의 데이터 셋이 저장되어 있어요.df(데이터 프레임)의 Sepal.Length부터 Petal.Width의 값들을 매트릭스 형태로 data에 할당해요.Species에는 ‘setosa’, ‘versicolor’, ‘virginica’ 값들이 있는데요. factorize() 을 이용하여 setosa는 0, versicolor는 1, virginica는 2로 바꿔줘요.# random splitX_train, X_test, y_train, y_test = train_test_split( data, target, test_size=0.4, random_state=0)X_train.shape, y_train.shapeX_test.shape, y_test.shape그다음에는 data와 target 데이터를 가지고 training set과 test set으로 6:4로 나눠요.X_train.shape = (90,4), X_test.shape = (60, 4)가 돼요.# LDA f = LinearDiscriminantAnalysis() f.fit(X_train,y_train) y_train_hat = f.predict(X_train) table_count(y_train,y_train_hat) f.score(X_train,y_train)LDA(Linear discriminant analysis)는 대표적인 확률론적 생성 모형이에요. 즉 y의 클래스 값에 따른 x의 분포에 대한 정보를 먼저 알아낸 후, 베이즈 정리를 사용하여 주어진 x에 대한 y의 확률 분포를 찾아낸다고 해요.Step2. test set 준비(1) LOOCV으로 test set 준비# leave-one-out from sklearn.model_selection import LeaveOneOutloo = LeaveOneOut()loo.get_n_splits(X_train)scv = []for train_idx, test_idx in loo.split(X_train): print('Train: ',train_idx,'Test: ',test_idx) f.fit(X_train[train_idx,:],y_train[train_idx]) s = f.score(X_train[test_idx,:],y_train[test_idx]) scv.append(s) get_n_splits() 함수를 사용하여 (90,4)의 shape을 가지는 X_train을 90개로 나눠요.test set에 0부터 89까지 하나씩 할당되고 할당된 숫자 외의 나머지 숫자들은 training set으로 모델을 검증해요. 위의 결과에서도 볼 수 있듯이 test set에 0이 할당되면 train set에는 1 ~ 89가 할당되어 모델을 검증하게 돼요!(2) K-fold CV로 test set 준비# K-fold CVfrom sklearn.model_selection import KFoldkf = KFold(5)kf.get_n_splits()scv = []for train_idx, test_idx in kf.split(X_train): print('Train: ',train_idx,'Test: ',test_idx) f.fit(X_train[train_idx,:],y_train[train_idx]) s = f.score(X_train[test_idx,:],y_train[test_idx]) scv.append(s) KFold(5) : 위에서 배운 k-fold 교차 검증에서 k를 5로 설정하여 우리가 가지고 있는 데이터 셋을 5개의 그룹으로 나눠서 교차 검증을 할 거예요.kf.get_n_splits()를 사용하여 5번 교차 검증할 것을 정해요.위에서 90개의 데이터셋을 5개의 그룹으로 나눴어요. 그리고 각 그룹 한 개씩 test set으로 정하고 나머지 그룹들은 training set으로 할당하고 모델을 검증해요. 예를 들어 그룹 1이 0~17, 그룹 2가 18 ~ 35, 그룹 3이 36~53, 그룹 4가 54~71, 그룹 5가 72~89라고 할 때, test set에 그룹 1을 할당하면 train set에는 그룹 2, 3, 4, 5가 할당되어 모델을 검증하게 돼요.Step3. 교차 검증 시행CV는 단순히 데이터 셋을 나누는 역할을 수행할 뿐이에요. 실제로 모형의 성능(편향 오차 및 분산)을 구하려면 이렇게 나누어진 데이터셋을 사용하여 평가를 반복해야 해요. 이 과정을 자동화하는 명령이 cross_val_score()이에요.# K-fold CVfrom sklearn.model_selection import cross_val_scoref = LinearDiscriminantAnalysis()s = cross_val_score(f,X_train,y_train,cv=3)cross_val_score(f, X_train, y_train, cv=3) : cross validation iterator cv를 이용하여 X_train, y_train을 분할하고 f에 넣어서 scoring metric을 구하는 과정을 반복해요.2. Regularization앞서 말한 우리의 목적은 우리의 데이터셋에 맞는 Y와 f를 구하는 것이었어요. f를 결정하기 위해서는 먼저 결정해야 하는 요소가 있어요. 아래 다섯 가지가 f를 결정하는 요소들이에요.- Model family : linear, neural 등 방법론 결정- Tuning parameter : 모델에 맞는 파라미터 조절 - Feature selection(특징 선택) : 많은 데이터 중 어떤 데이터를 쓸지 고르는 것 - Regularization(정규화) - Dimension reduction(차원 축소)f를 결정하는 요소 중 Regularization(정규화)에 대해 알아볼게요!정규화 선형회귀 방법은 선형회귀 계수(weight)에 대한 제약 조건을 추가함으로써 모형이 과도하게 최적화되는 현상(과최적화, overfitting)을 막는 방법이에요. 모형이 과도하게 최적화되면 모형 계수의 크기도 과도하게 증가하는 경향이 나타나요. 따라서 정규화 방법에서 추가하는 제약 조건은 일반적으로 계수의 크기를 제한하는 방법이에요. 일반적으로 Ridge Regression, Lasso, Elastic Net 이 세 가지 방법이 사용돼요.Ridge Regression머신 러닝에서는 모델의 오차를 찾기 위해 보통 최소제곱법(Least squares fitting)을 이용하여 β를 최소화시켜요. 위의 RSS는 잔차제곱식으로 예측값과 실제 값 사이의 차이를 구하는 식이에요. 회귀분석의 계수 값을 RSS을 최소화하는 β값을 찾음으로써 구할 수 있어요.Ridge Regression은 최소제곱법에 가중치들의 제곱합을 최소화하는 것을 추가적인 제약 조건으로 갖는 방법이에요. λ는 기존의 제곱합과 추가적 제약 조건의 비중을 조절하기 위한 하이퍼 파라미터에요. λ가 크면 정규화 정도가 커지고 가중치의 값들이 작아져요. λ가 작아지면 정규화 정도가 작아지며 λ가 0이 되면 일반적인 선형 회귀 모형이 돼요.코드로는 아래와 같이 나타낼 수 있어요.from sklearn.linear_model import Ridgef = Ridge(alpha=0.5)f.fit(xtrain,ytrain)f.intercept_,f.coef_f.score(xtrain,ytrain)f.score(xtest,ytest)LassoLasso는 가중치의 절댓값의 합을 최소화하는 것을 추가적인 제약 조건으로 가져요. 아래와 같이 코드로 나타낼 수 있어요.from sklearn.linear_model import Lassof = Lasso(alpha=1.0)f.fit(xtrain,ytrain)f.intercept_,f.coef_f.score(xtrain,ytrain)f.score(xtest,ytest)Elastic NetElastic Net은 가중치의 절댓값의 합과 제곱합을 동시에 제약 조건으로 가지는 모형이에요. 코드로는 아래와 같아요.from sklearn.linear_model import ElasticNetf = ElasticNet(alpha=0.1,l1_ratio=0.5)f.fit(xtrain,ytrain) f.intercept_,f.coef_f.score(xtrain,ytrain)f.score(xtest,ytest)Lasso와 Ridge Regression의 차이점왼쪽 : Lasso, 오른쪽 Ridge Regression위의 두 그림은 Lasso와 Ridge Regression의 차이점을 잘 나타내는 그림이에요. 초록색 부분은 회귀계수(회귀분석에서 독립변수가 한 단위 변화함에 따라 종속변수에 미치는 영향력 크기)가 가질 수 있는 영역이고 빨간색 원은 RSS가 같은 지점을 연결한 것을 보여주는 것으로 가운데로 갈수록 오차가 작아져요.Lasso와 Ridge Regression 모두 RSS를 희생하여 계수를 축소하는 방법이라는 공통점이 있어요.하지만 Ridge Regression과 Lasso의 가장 큰 차이점은 Ridge 회귀는 계수를 축소하되 0에 가까운 수로 축소하는 반면, Lasso는 계수를 완전히 0으로 축소화한다는 점이에요.Cross validation(교차 검증)과 Regularization(정규화)에 대해 알아보았는데요. 간단히 요약해 볼게요.Cross validation(교차 검증)은 머신러닝 모델의 타당성을 검증하는 방법 중의 하나로, 특정 데이터를 training set과 test set으로 분할한 뒤 training set을 활용해 학습하고 test set으로 테스트하여 학습의 타당성을 검증하는 방법이에요. 교차 검증에는 여러 가지 방법이 있는데 그중에서도 우리는 LOOCV와 K-Fold CV를 배웠어요.Regularization(정규화)는 모델의 일반화 오류를 줄여 과적합을 방지하는 방법을 말해요. 일반적으로 Ridge Regression, Lasso, Elastic Net 이 세 가지 방법을 사용해요.이상적인 머신러닝 모델을 만들기 위해 고려해야 할 점들은 정말 많은 것 같아요. 우리가 만든 모델이 적합한 모델인지 이번 수업시간에 배운 교차 검증과 정규화를 통해 잘 살펴봐요!* 이 글은 AI스쿨 - 인공지능 R&D 실무자 양성과정 4주차 수업에 대하여 수강생 최유진님이 작성하신 수업 후기입니다.


























.png)