조회수 2947
WHATAP Python APM 이야기...
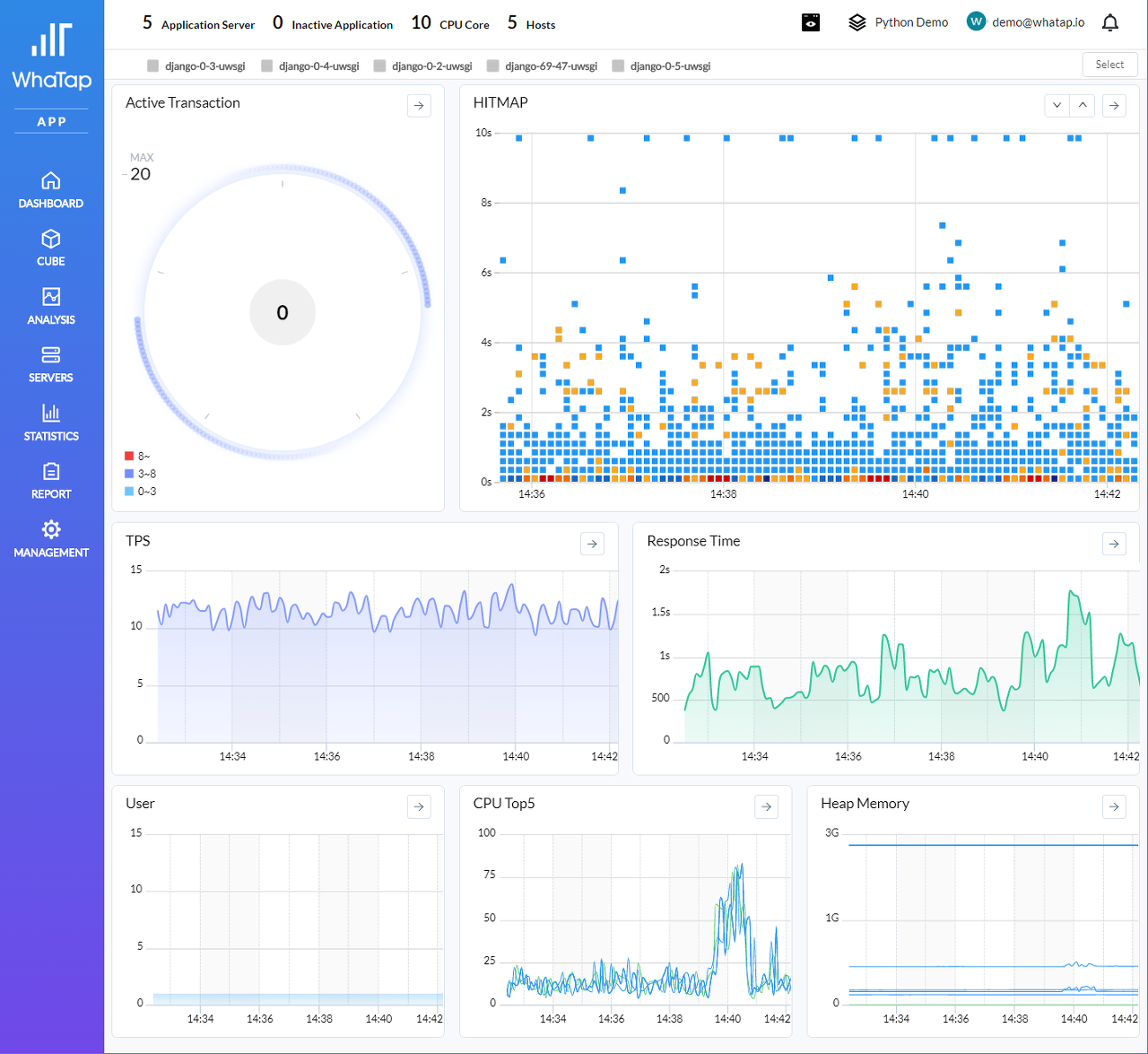
백엔드 서비스로 Python을 사용한다면 만나게될 상황을보다 쉽게 해결하기 위한 와탭의 Python APM, 개발하게 된 이유입니다.파이썬은 배우기 쉽고, 어디서나 실행되는 언어라고 이야기되며, 인기도 높습니다. 생각보다 많은 곳에서 배울 수 있으며, 혼자 배우기도 좋습니다. 그런데, 이 규모가 확대되어서 스타트업의 경우에 Python을 사용하여 백엔드 서비스를 개발하는 경우를 찾는 것이 어렵지 않습니다. 또는, 수학적인 알고리즘이거나 ML(머신러닝)과 같은 영역이거나 블록체인등에서 Python을 사용하여 API geteway나 broker를 사용하는 경우에 한정한 상황을 고려하고 있습니다.Python으로 백엔드 서비스를 만들 때에는 성능과 설계 부분에 대해서 많은 걱정을 하게 됩니다. 이런 상황을 만나게되는 개발자는 여러가지 문제를 만나게 됩니다. 그 문제에 와탭은 집중합니다.!와탭은 백엔드 서비스를 Python으로 개발시에 만나게 되는 상황을 가장 최우선으로 생각하게 되었습니다.Python으로 '설계', '개발'되고 '테스트'된 후에 '배포'되는 상황에서 서비스의 불완전함과 속도상의 문제, 리소스의 불협화음등을 '유지보수'하는 단계를 '성능 튜닝'이라고 정의하고, 이를 고려한 상황을 보다 단순화하는 것이라고 생각하게 되었습니다. 이를 어떻게 처리하느냐가 와탭 Python의 핵심 가치라고 생각하였습니다.----- 이 부분은 Python korea 페이스북에서 '배권한'님이 지적하신 내용을 기반으로 일부 첨언되었습니다.----- python native 개발자들에게는 불필요한 설명에 해당됩니다.파이썬은 분명, 읽기 쉽고 사용하기 쉬운 것은 장점이며, 라즈베리파이 위에서 동작되는 기민함은 정말 매력적입니다. <- 원래 문장.(* 현재에는 jvm도 동작합니다. 하지만, 작고 기민하게 다양한 IoT 디바이스에서 폭넓게 활용되는 것은 파이썬의 장점은 분명하지 않나 합니다. 이 부분에 대한 지적이 있어서 첨언합니다. )내부 구성상 비동기식으로 쓰레딩이 아니라, 단일 이벤트 루프를 사용하는 비동기식 작성은 매우 효과적입니다. <- 원래 문장.(* 이 부분도 asyncio나 gevent등에 대한 이야기이고, CPython의 언어 구현상 GIL때문에 쓰레드가 비효율적이라는 이야기를 거론하고 싶었으나, 일반적으로 파이썬에 대한 언어를 사용할때에 대부분 사용하는 이유가 단일 이벤트 루프기반의 비동기식 작성이 매우 일반적으로 사용되기 때문에, 이렇게 서술되었습니다. 하지만, 이런 설명은 백엔드로 Python을 사용하는 경우에 대부분의 프레임웍들에서 처리되고 있기 때문에 서술이 불분명하다는 지적이 있었습니다. 당연, 백엔드 서비스를 개발할때에 사용되는 wsgi interface등에 맞추어서 서술되는 경우에는 이런 설명이 무의미합니다.다만, 이렇게 서술한 이유는 Java를 기반으로 APM이 개발되어졌기 때문에 이 부분에 대한 서술이나 설명이 필요하다고 생각한 저의 과도한 설명이 되겠습니다.이 부분은 Python Native개발자들에게는 불필요한 설명이 되겠습니다. 하지만, 백엔드 서비스를 개발하면서 만나게될 환경에서는 이 부분에 대한 이해가 어느정도 필요하다고 생각되어 서술된 내용이라고 생각해주시면 감사하겠습니다. )----------------------------------------------------------------------------------------------------------------------이 방식은 복잡한 자원 경쟁이나 교착상태를 발생하지 않게 되며, 기본 코딩과 유지보수를 정말 수월하게 만들어 줍니다. 그만큼 일관성이 높은 수학 알고리즘을 구현하는데 매우 적합합니다. 하지만, 냉정하게, 비즈니스 로직이나 분기가 많은 업무 로직에 적합한 언어는 아닙니다.하지만, 수학적 알고리즘 기반의 주요 모듈 위에 데이터베이스가 일부 필요하고, 웹서비스의 형태로 가동되는 구조라면 파이썬은 매우 훌륭한 선택이 되고 있으며, 생각보다 많이 사용됩니다.그런 이유 중의 하나는 파이썬의 멀티패러다임 구성과 같은 구성에서는 자바에서처럼 굳이 프린트를 위해서 객체지향 클래스를 만들 필요 없이 간단한 함수형 스타일도 가능하게 구성이 됩니다. ( 자바 8에서는 이런 함수 기능도 추가되었습니다. )단순한 구조와 방식 때문에 파이썬 개발은 요즘처럼 ML이나 AI 등의 기술적 요소들이 많이 사용되는 환경에서는 매우 효과적입니다. 백엔드 파이썬 개발이 많이 보이게 되는 이유이기도 하죠.또한, 파이썬 개발의 단점이라고 지적되던 문제들도 현재에는 실행 속도 문제는 사실상 큰 문제가 되지 않는 상황입니다. 일례로, 파이파이(PyPY)로 실행된 파이썬 코드는 웬만한 수준의 C 코드보다 빠르게 동작합니다.굳이 더 지적하자면, 모바일 컴퓨팅과 브라우저에 따른 웹 애플리케이션 클라이언트는 굳이 파이썬으로 작성할 필요성을 느끼지 못한다고 이야기하는 정도입니다.하지만, 이런 파이썬 개발에 가장 큰 문제가 있습니다.테스팅 없이는 동작하기 어렵고,실제 동작 환경에서만 등장하는 오류의 발생파이썬의 특성상 동적 입력 형태에 따르는 더 많은 테스팅을 필요로 하고 있으며, 실제 실행시간에만 나타나는 오류를 찾는 것이 가장 큰 문제가 있습니다. 이 부분은 수많은 파이썬 개발자들을 괴롭히고 있습니다.( 단편적으로 파이썬 개발환경이 매우 고도화되어있지 않으며, 파이썬으로 백엔드 서비스를 만들 것이라고 예측하지 못한 점도 있을 것입니다. 앞으로 파이썬 개발이 더 고도화 되기를 기원합니다. )이 가장 큰 문제를 잡기 위해서와탭은 집중하였습니다.파이썬 백엔드 개발 시의 문제 해결!물론, Python도 디버깅에 대한 지원 유틸리티가 존재합니다.pdb라는 파이썬 디버깅 모듈을 통해서 Step over/Step into, 중단점(breakpoint) 설정, 콜 스택 검사, 소스 리스팅, 변수 치환 등을 할 수 있습니다.‘Phthon -m pdb 파이썬 파일. py’의 형태로 디버그 동작 화면에서 세부적인 동작을 트레이스 해보는 방식을 사용하거나, pdb모듈을 import 한 후에 pdb.set_trace()를 중단하고 싶은 부분에 넣어서 사용하는 방식도 사용됩니다. 또한, 디버그 세션을 사용하는 방식이며, PDB를 사용하여 디버깅하는 방식들도 흔하게 사용됩니다.PyCharm, PTVS, Spyder 등의 IDE를 사용해서 디버깅을 하는 방법은 전통적인 개발환경과 동일하게 사용할 수 있습니다.하지만, 이 방식들은 백엔드 서비스에는 맞지 않게 되며 개발자들은 백엔드 서비스 동작시에 디버그 추적을 위한 로그를 거는 방식을 흔하게 사용하게 됩니다. ( 너무도 전통적인 방식이죠. )정말 백엔드로 파이썬을 사용하고 있다면, 오류 추적이나 동작 메커니즘을 추적한다는 것은 매우 귀찮고 번거로운 작업이 됩니다.만들어지는 파이썬의 모든 파일에 해당 로그를 넣었다가 빼었다가, 배포의 오류를 만나는 상황까지 매우 번거로운 작업들이 끊임없이 반복되게 됩니다. 이런 상황들을 추적하기 위한 APM의 추적 기능들을 찾게 됩니다.또한, Python의 특징상 수학 알고리즘으로 구성된 API 중개인의 형태를 취할 경우에 DB에 대한 접근을 위한 ORM에서의 추적과 외부 웹 호출들이 뒤섞이게 되면서 오류 추적은 매우 짜증스러운 단계로 진화되게 됩니다.Python으로 백엔드 개발을 하게 되면만나게 되는 매우 짜증스러운 상황이죠.그래서, 와탭의 Python APM은 이 문제에 집중하기 위해서 와탭 고유의 문제 해결 방식을 그대로 아키텍처로 적용하여서 개발시에 편하고 빠르게 성능을 추적할 수 있도록 제작되었습니다. Python 백엔드 개발을 위한 최선의 방향을 제시합니다.Python개발자는 와탭의 APM을 설치하면 매우 손쉽게 웹 트랜잭션의 단계, 에러 추적, 클래스 추적, DB의 형태 및 Slow Query추적, 외부 호출 메커니즘의 구성 등을 설치 이후부터 빠르게 추적할 수 있으며, 개발자의 실수이거나 다른 외부 호출의 문제, DB와의 관계 등을 빠르게 잡아낼 수 있습니다.에러를 추적하기 위한 로그를 동작한다던지, 실환경시에 배포를 다시 한다던가 하는 귀찮은 작업을 모두 제거하는 것뿐만 아니라, 매우 통계적으로 의미 있는 와탭의 트랜잭션 추적 메커니즘을 사용할 수 있게 됩니다.파이썬을 기반으로 백엔드를 구성하는 곳이라면,와탭 APM은 매우 의미 있는 결과를 도출할 수 있습니다.와탭 Python의 세부적인 기능을 조금 더 상세하게 설명드리겠습니다.가장 먼저, 실시간 트랜잭션 모니터링!5초 주기로 트랜잭션을 수집하는 와탭의 방식은 서버의 부하를 최소화하면서 가장 의미 있는 데이터들을 수집하고 데이터 기반으로 오류와 트랜잭션을 빠르게 추적할 수 있게 합니다.파이썬 개발 시의 동작성을 체크하기 위한 와탭만의 고유의 진행 중인 트랜잭션 실시간 모니터링 기능인 아크 이퀄라이져와 동작된 웹 트랜잭션의 종료시간을 기준으로 시각화하여 동작된 트랜잭션의 상황을 한눈에 파악할 수 있습니다.와탭 Python APM위의 그림을 보면, Active Transaction으로 불리는 원형( 아크 이퀄라이져라 함 )으로 실제 동작중인 트랜잭션의 개수와 동작속도 등을 체크할 수 있으며, Hitmap을 통해서 종료된 트랜잭션의 속도를 시각화하여 볼 수 있습니다. 이 두 개의 시각화 만으로도 느린 트랜잭션을 추적 관리할 수 있습니다.Python 트랜잭션 추적 및 분석개발자는 단지 APM을 동작시켰을 뿐이지만, postgreSQL 데이터베이스에 연결하고 SQL문장을 주고받는 부분들을 하나의 시각화된 관점으로 나열해서 확인할 수 있습니다.각각의 동작 시간을 추적하는 것은 물론이고, 이 내용은 ORM으로 매핑된 상태에서도 SQL의 동작 순서대로 시각화되기 때문에 순서가 꼬이거나 문제가 발생되는 부분들을 손쉽게 찾아볼 수 있게 합니다.이외에도 와탭 APM( Java, Node, PHP 등의 모든 APM)에 기본적으로 제공되는 트랜잭션 추적 모듈 이외에도 사용자가 원하는 모듈 추적에 대한 기능들을 플러그인 형태로 정의할 수 있습니다. 더 복잡한 추적을 위해서 와탭의 고유기능을 추가적을 확대 사용이 가능합니다.WHATAP_HOME 의 plugin.json파일에 적절한 내용을 수정하여 특정 모듈의 데이터를 추적할 수 있습니다. 특정 모듈의 데이터를 추적하거나, 사용자 별로 원하는 모듈을 추적할 수 있습니다.*사용 안내:•[module_name]: 추적하고자 하는 대상의 모듈 명. import 하는 모듈 명 이기도 하다.•[class_name]: 추적하고자 하는 대상의 클래스 명. 없다면 ‘’(empty string)으로 사용한다.•[def_name]: 추적하고자 하는 대상이다.•args_indexes: 추적하고자 하는 대상의 아규먼트 인덱스. 여러 개일 경우 , 로 구분한다.•kwargs: 추적하고자 하는 대상의 키워드 명. 여러 개일 경우 , 로 구분한다.Plugin 기능 사용위의 예제에서는 Plugin과 SQL update문장의 순차적인 실행,세부 Plugin 설정에서 사용자의 모듈명, 추적 클래스 명, 추적대상과 아규먼트 인덱스, 키워드 등을 추적할 수 있습니다.*사용 예:plugin.json{"[module_name]": { "class_name": "[class_name]", "def_name": "[def_name]", "args_indexes": ", ", "kwargs": ", "},"httplib2": { "class_name": "Http", "def_name": "request", "args_indexes": "1", "kwargs": "method"},"faker.providers.address": { "class_name": "Provider", "def_name": "street_address", "args_indexes": "", "kwargs": ""}}두 번째, 데이터베이스를 매핑한 ORM과 SQL의 순서와 속도, Slow Query!매우 당연하게 파이썬을 기반으로 백엔드 개발을 할 경우에 데이터베이스를 사용하게 되며, 이에 대한 Slow Query와 관련된 추적하는 것이 개발자에게 필요하게 됩니다. 향후, RDS기반을 사용하게 되면 Query추적은 대부분의 데이터베이스 처리에 기본이 될 것입니다.현재 지원되고 있는 mysql / postgresql에 대하여 SQL Query, Fetch Count, SQL Query수행 시간을 수집합니다.Python개발 시에 RDBMS(관계형 데이터베이스 관리 시스템)를 선택하면 거의 항상 ORM(객체 관계 매핑) 라이브러리를 함께 사용하게 됩니다.특히, 파이썬에서는 이런 ORM라이브러리가 다양하고 사용하기 쉽기 때문에, 매우 흔하게 사용하고 있습니다.ORM의 장점으로는 쿼리를 생성하거나 추상화하는 대신, 데이터 베이스 시스템에 대한 접근을 쉽게 할 수 있는 장점이 있습니다. 다만, 이러한 장점 때문에 실제 만들어진 쿼리가 어떠하고 쿼리 수행 시간이 얼마나 걸리는지에 대해서는 추적이 어렵다는 점이 있습니다.이처럼, 파이썬의 특징상 ORM(객체 관계 매핑) 라이브러리를 사용할 경우에 추상화된 쿼리가 어떻게 동작하고, 실제 어떤 상황으로 발생 및 동작되는지를 한눈에 파악할 수 있게 합니다.ORM으로 매핑된 SQL의 순차적인 동작 상태 파악그리고, 세 번째. 외부 호출 추적파이썬 백엔드 개발 시에 사용되는 외부 호출(request/httplib2)등의 외부 호출과 관련된 호출 정보 및 수행 시간 등을 수집합니다.외부 호출을 사용하는 경우에는 각각의 호출에 대한 지연시간에 대해서 세밀하게 추적해야 하므로, 이와 관련된 에러와 지연시간 등을 추적하는 것은 매우 중요한 개발 시의 관점입니다.Python 외부 호출 추적마지막 중요 관점 네 번째는, 튜닝을 위한 다양한 프로파일 데이터의 제공을 이야기할 수 있습니다.와탭의 파이썬 에이전트는 위에서 나열되는 성능 저하를 위한 요소들의 전체적인 관점에서 수집하고 그 데이터들을 시각화할 수 있습니다.데이터베이스를 효율적으로 사용하고 있는지, 사용하는 ORM툴과 매핑과의 관계, 쿼리와 쿼리의 수행 시간과 상태에 대한 추적, 외부 호출시간과 각각의 지연되는 외부 호출과의 관계와 순서 등이 전체적으로 백엔드로 개발되는 Python의 성능 튜닝에 영향을 주게 되는 것이죠.그 이외에도 전체적으로 백엔드 서비스의 TPS, 응답 시간, 서비스 리소스 사용량과 어떤 에러가 발생되고 있는지를 알 수 있습니다.서비스 사용자가 사용하는 상세한 정보들을 프로파 일릉 함으로써 이들의 연관관계를 한분에 파악하게 해줍니다. 와탭에서 관리되는 프로파일 정보는 - 트랜잭션, SQL Query, 외부 HTTP호출, Error, User Agent, Client IP 등의 상관관계들입니다.그리고, 덤으로... Python이 설치 운영되는 전체적인 패키지의 버전을 한눈에 파악할 수 있는 것은 너무도 당연한 기능입니다.설치된 Python 패키지 확인그리고, 와탭의 DNA를 그대로 이어받은 APM이기 때문에, 기본적인 APM의 기능들을 대부분 담고 있습니다. 처음 와탭 APM을 접하시는 분들을 위해서 간단하게 설명드리면 다음과 같습니다.CUBE 메뉴는 시간을 기점으로 와탭 Python APM이 설치된 이후부터 현재까지의 모든 상황들을 추적 관찰할 수 있습니다. 주말에 오류 간 난 상황이라던지, 특정 오류의 발생 시점을 알고 있는 경우에 빠르게 해당 문제가 발생한 위치나 SQL 등을 추적할 수 있습니다.상세한 일간, 주간, 월간 리포트나 MAU 등을 추적할 수 있는 리포트 기능들은 와탭만이 가지고 있는 장점에 해당됩니다.Python으로 백엔드 웹서비스를 개발하고 계시다면, WHATAP Python APM은 개발과 운용을 매우 풍요롭고 빠르게 해줍니다.파이썬 백엔드 서비스 개발자라면 와탭 APM!